
Flux 모델을 위한 LoRA 학습을 진행하려면, 특정 인물의 특징을 반영할 수 있는 충분한 양질의 이미지 데이터셋이 필요합니다. 그러나 인터넷에서 가져온 사진이나 실제 인물의 사진을 사용할 수 없는 법적·윤리적 제약이 있기 때문에, 학습에 적합한 데이터를 직접 생성해야 합니다. 이를 해결하기 위해 생성 AI 기반 비디오 모델을 활용하여 LoRA 학습용 이미지를 제작하려고 합니다.
생성 AI 비디오 모델을 이용하면 일관된 스타일과 조명을 유지하면서도, 다양한 각도와 표정을 포함한 고품질 데이터셋을 구축할 수 있습니다. 특히, 특정 스타일이나 개성을 가진 인물을 학습시키려면 다양한 포즈와 조명 환경에서 촬영된 이미지가 필요한데 비디오 모델을 사용하면 이러한 요구를 충족하는 프레임을 쉽게 추출할 수 있습니다.
기술적으로는 AI 비디오 생성 모델을 사용하여 5~10초 길이의 클립을 제작한 후, 이를 프레임 단위로 분해하여 이미지 데이터셋을 구성하는 방식이 이상적입니다. 이후, Flux 모델의 특성에 맞게 이미지 보정, 해상도 및 노이즈 정리 등의 전처리 과정을 거쳐 학습을 위한 데이터셋을 준비하려고 합니다.
이러한 접근 방식은 기존의 데이터셋을 사용할 수 없는 환경에서도 맞춤형 인물 LoRA 학습을 가능하게 하며, 원하는 개성을 반영한 이미지를 생성하는 것이 가능하게 합니다. 다음 섹션에서는 이러한 생성 데이터를 효율적으로 정리하고 전처리하는 방법에 대해 다루겠습니다.
2-3-1. Google DeepMind ImageFX를 활용한 인물 인물 제작
ImageFX는 Google DeepMind의 최신 텍스트-이미지 생성 모델인 Imagen 3을 기반으로 한 도구로, 사용자가 텍스트 프롬프트를 입력하면 고품질의 이미지를 생성합니다. 이 도구는 Expression Chips 기능을 통해 다양한 스타일과 분위기의 이미지를 손쉽게 탐색할 수 있도록 지원합니다. 특히, ImageFX는 동양인 이미지를 매우 사실적으로 표현하는 데 탁월한 성능을 보입니다.(최근에 RunwayML에서 공개한 Text-to-Image 모델인 Frames도 동양인을 잘 표현해 냅니다. ImageFX의 표현은 콘트라스트가 Frames에 비해서 좀 강한 것 같습니다.) 이는 다양한 데이터 학습과 향상된 모델의 표현력 덕분이라고 생각이 됩니다, 한국인을 포함한 동양인의 특징을 자연스럽게 반영하고, 사용자 친화적인 인터페이스를 제공하여 누구나 쉽게 접근하고 창의적인 이미지를 ImageFX에서 생성할 수 있습니다.
아래의 이미지는 ImageFX의 인터페이스 입니다. 인터페이스는 직관적이고 기존의 다른 여러 플랫폼이나 서비스와 유사하기 때문에 따로 설명은 하지 않도록 하겠습니다.
평범해 보이는 사실적인 동양인 여성의 이미지가 필요하기 때문에 아래와 같이 프롬프트를 작성해서 이미지를 생성했습니다.
A captivating portrait of a Korean woman with black hair, with minimal makeup, dressed in a white shirt and blue jeans. Shot in a studio with soft lighting and subtle shadows. Photorealistic, highly detailed, raw image.
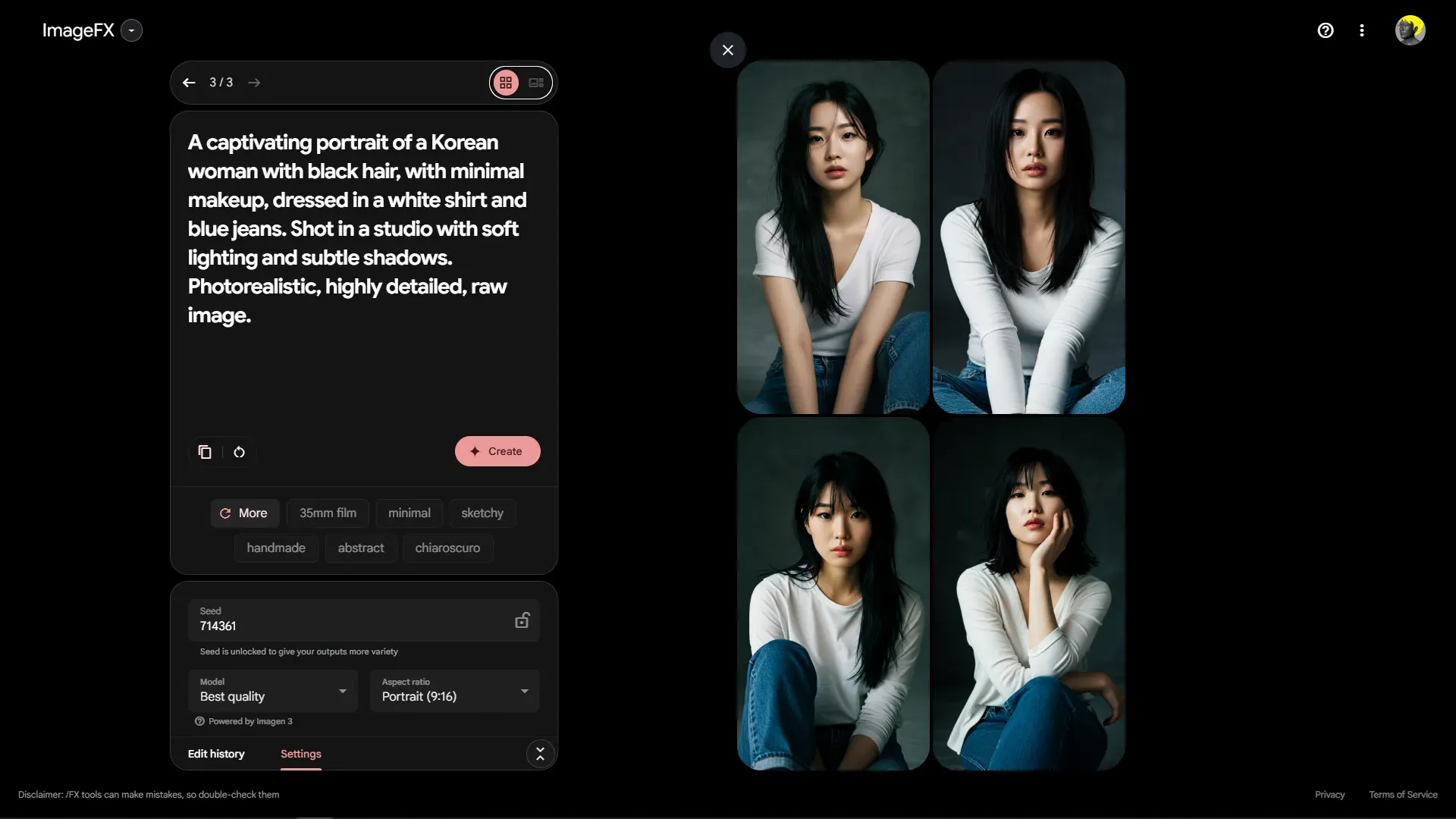
여러가지 이미지를 생성했었고 최종적으로 아래와 같은 이미지를 선택 했습니다. 이 이미지는 AI 학습용 데이터로 활용하기 위해 제작된 것으로, 자연스럽고 사실적인 인물 표현을 목표로 했습니다. 배경은 미니멀한 스튜디오 톤으로 설정하여 피사체에 집중할 수 있도록 하였으며, 의상은 심플한 화이트 셔츠와 데님을 선택해 깔끔한 인상을 강조했습니다. 얼굴은 부드러운 조명과 적절한 대비를 통해 세밀한 피부 질감과 구조를 강조하며, 눈빛과 표정에서 자연스러움과 진정성을 담아내는 것을 목표로 했습니다. 또한, 헤어 스타일은 자연스러운 웨이브와 질감을 유지하면서도 선명한 디테일이 표현되었습니다.

2-3-2. Kling AI를 활용한 다양한 각도의 이미지 제작
Kling AI의 Image-to-Video 기능을 활용하여 단일 이미지에서 다양한 포즈와 자연스러운 움직임이 포함된 비디오를 생성하려고 합니다. 이후, 생성된 비디오에서 프레임을 추출하여 다양한 각도와 자세를 반영한 학습용 데이터셋을 준비하려고 합니다. 이를 통해 일관된 스타일을 유지하면서도 다채로운 포즈를 포함한 LoRA 학습 데이터를 효과적으로 확보할 수 있습니다.
일단 아래의 이미지와 같이 이미지 프롬프트 만으로 idle한 포즈를 취하도록 합니다.

이번에는 이미지 프롬프트와 같이 텍스트 프롬프트로 the camera is stationary라는 프리셋 프롬프트를 사용해서 카메라를 고정 시키고 The model looks sideway라는 프롬프트로 인물이 측면을 보게 유도합니다.

프롬프트 입력창 우측 상단에 Get Inspirations를 클릭하면 아래의 이미지와 같이 Prompt Dictionary에서 몇 가지 카메라 관련된 프롬프트 프리셋을 찾으실 수 있습니다.

the camera rotates around the subject란 프롬프트로 카메라가 인물을 중심으로 회전해서 측면 뷰 등을 얻을 수 있도록 영상을 생성 했습니다.

이번에는 the camera zoom in 이라는 프롬프트를 통해서 인물의 얼굴이 좀 더 화면 차게 생성했습니다.

그 다음은 다양성을 위해 전신 이미지가 필요해서 the camera zoom out을 통해서 인물의 전신이 나오도록 영상을 생성 했습니다.

지금까지 Kling AI로 생성된 영상의 사양은 아래와 같습니다.
1.
해상도 : 1184 x 1696 (ImageFX에서 이미지를 생성할 떄 3:4 비율로 생성했기 때문입니다.)
2.
프레임레이트 : 30fps
3.
듀레이션 : 5s~10s
2-3-3. 영상 편집
블렌더의 VSE(Video Sequence Editor)에서 지금까지 생성된 영상을 하나로 이어 붙였습니다. 블렌더에는 3D 툴이지만 간단한 이미지 시퀀스 편집기가 있어서 간단한 작업들은 블렌더 VSE등을 이용해서 하고 있습니다. 가볍고 빠르기 때문에 영상의 시작 프레임과 끝 프레임을 추출하거나 하는데 활용하고 있습니다.

아래의 이미지는 지금 까지의 생성된 영상을 하나로 이어 붙여서 렌더링 한 영상의 결과입니다.
아래의 이미지들은 위의 영상에 인물의 다양한 뷰와 표정을 추출한 이미지들 입니다. 그리고 학습에 용이하게 1:1 비율로 이미지를 정리 했습니다. 추가적으로 얼굴의 표정 변화 시킨 부분이 있는데 이것은 이어지는 챕터에서 설명할 RunwayML의 Act-One의 기능을 이용해서 만든 표정들 입니다.

추가로 또다른 생성 AI 비디오 플랫폼인 Pixverse를 이용해서 턴테이블을 제작한 경우입니다. Pixverse에서는 최근에 Pika와 같이 여러가지 이펙트들을 출시 했습니다. 턴테이블은 Pixverse에서 최근(2025.03)에 추가된 가장 인기있는 이펙트중 하나일 것입니다. 한 장의 이미지를 통해서 인물의 360뷰를 구성한다는 것은 향후에 3D로도 만들 수 있는 가능성도 가지고 있습니다. Pixverse에서 턴테이블을 제작하는 방법은 챕터3(3-9)에서 설명 드리도록 하겠습니다 이 턴테이블을 통해서 위의 방법에서 얻지 못했던 완전한 측면 이미지를 얻을 수 있었습니다. 보통 3D 모델링을 할 때에도 레퍼런스로 완전한 측면 이미지를 얻기가 힘들었는데 이제는 생성 AI를 통해서 손 쉽게 얻을 수 있는 시대가 되었습니다.
아래는 그 결과의 영상입니다.
1896x1280
위의 영상들을 통해서 아래와 같은 이미지들을 얻을 수 있었습니다.

2-3-4. Kling AI의 Elements를 활용한 다양한 의복과 포즈 이미지 생성
지금까지 Kling AI와 Pixverse로 인물의 다양한 뷰를 얻었다면 이번에는 다양한 의상과 포즈를 얻도록 하겠습니다. Kling AI에 최근에 Elements라는 새로운 기능이 추가 되었습니다.
Kling AI의 Elements 기능은 여러 개의 레퍼런스 이미지를 조합하여 영상을 생성할 수 있는 기능입니다. 이 기능을 통해 인물, 배경, 오브젝트 등의 이미지를 결합하여 더욱 정교하고 일관성 있는 영상을 제작할 수 있습니다. 예를 들어, 바닷가 풍경과 서핑보드를 든 사람의 이미지를 각각 업로드하고 'a person surfing on the ocean'과 같은 텍스트 프롬프트를 입력하면, 해당 인물이 실제로 바다 위에서 서핑을 하는 영상을 생성할 수 있습니다.
또한, Elements 기능은 패션 화보 제작에도 유용합니다. 의류 브랜드의 제품 사진을 업로드하면, 모델이 해당 옷을 입고 걷거나 포즈를 취하는 영상으로 변환할 수 있어 패션 홍보 콘텐츠 제작이 간편해집니다.
이러한 Elements 기능을 이용하여 학습 시키기 위한 데이터를 추가해보겠습니다.
Kling AI의 대시보드에서 Elements 탭을 클릭하면 아래와 같은 인터페이스를 확인하실 수 있습니다.

설명에 있듯이 1-4개의 이미지를 업로드 할 수 있습니다. 지원하는 포멧은 *.jpg또는 *.png를 지원하고 있습니다. 각 이미지마다 10mb가 최대 사이즈이고, 최소 픽셀은 한쪽이 300px 정도 입니다.

ImageFX에서 만든 인물의 이미지와 참고할 의류 이미지와 배경 이미지를 아래와 같이 업로드하고 아래와 같은 프롬프트를 입력했습니다. 노란색 정장을 입고 외국의 거리에서 포즈를 취하는 컨셉으로 영상을 생성 했습니다. 영상의 비율을 학습에 용이하게 하기 위해서 1:1 비율로 했습니다.

같은 방식으로 몇 가지 옷을 인물에 입히고 다양한 배경 앞에서 포즈를 취하는 영상들을 아래와 같이 생성 했습니다.
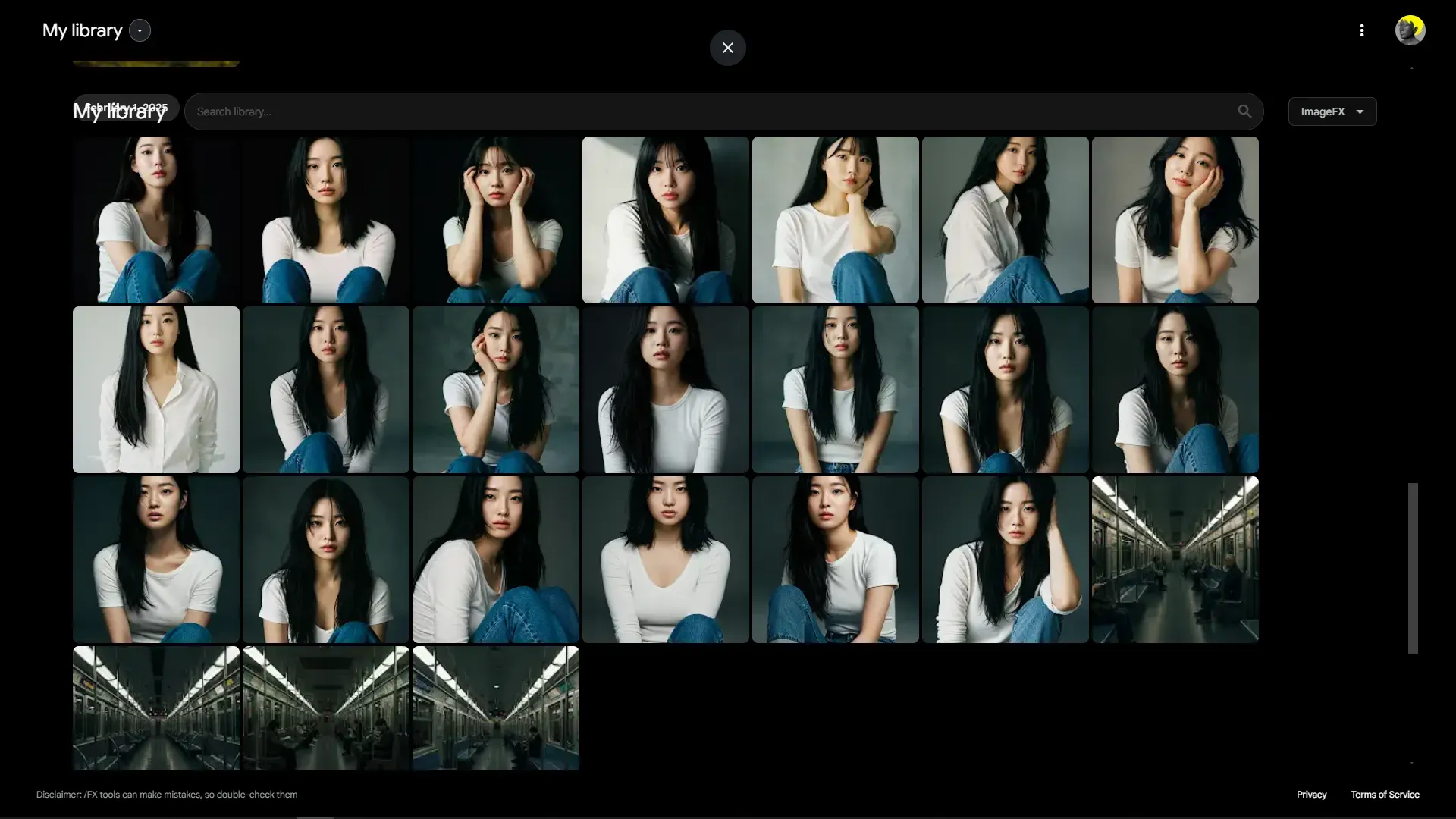
그리고 아래와 같이 생성된 영상들에서 학습에 사용할 만한 이미지들을 추출 했습니다. 이미지를 추출하기 위해서 선택한 영상의 프레임 기준은 최대한 ImageFX로 만든 인물의 인상과 가장 흡사하고 인물의 얼굴과 포즈가 무너지지 않으며 인물의 뒤에 있는 배경에 심한 변형이 일어나지 않는 프레임 이었습니다. 저의 경우 아래와 같은 14개의 이미지가 적당하다고 생각되어 아래와 같이 정리 했습니다.

2-3-5. LoRA 학습을 위한 데이터 라벨링(캡셔닝) 하기
LoRA 학습에서 라벨링(캡셔닝)의 필요성
LoRA 학습에서는 모델이 주어진 이미지에서 어떤 특징을 학습할지를 결정해야 합니다. 이를 돕기 위해 이미지에 라벨링(캡셔닝)을 추가하는 과정이 필요합니다. 라벨링이란 이미지의 주요 요소를 설명하는 텍스트 태그를 의미하며, 모델이 특정 개념을 더 잘 이해하고 학습할 수 있도록 도와줍니다.
라벨링(캡셔닝)이 필요한 이유
•
모델이 어떤 개념을 학습해야 하는지 명확하게 정의할 수 있습니다.
•
특정 키워드를 프롬프트로 입력했을 때 원하는 결과를 얻을 가능성이 높아집니다.
•
학습된 데이터가 더 다양한 상황에서 활용될 수 있습니다.
•
오버피팅을 방지하고, 학습 데이터의 일반화를 돕는 역할 수행합니다.
라벨링 없이 LoRA 학습하는 경우 vs. 라벨링과 함께 학습하는 경우 비교
구분 | 라벨링 없이 학습 | 라벨링과 함께 학습 |
학습 방식 | 단순한 픽셀 패턴 학습 | 의미 기반의 개념 학습 |
장점 | 특정 스타일이나 개체를 강하게 학습할 수 있음 | 텍스트 프롬프트 기반으로 자유롭게 이미지 생성 가능 |
단점 | 프롬프트를 사용하여 제어하기 어려움 | 적절한 캡셔닝이 필요하며 추가적인 작업이 필요함 |
적용 예시 | 특정 캐릭터 얼굴 학습, 특정 카툰 스타일 학습 | 특정 인물 스타일의 포즈, 조명 조건 등을 텍스트로 제어 |
라벨링 없이 학습할 경우, 모델은 단순한 이미지 패턴을 학습하기 때문에 특정 스타일이나 개체를 매우 강하게 기억할 수 있습니다. 하지만 이렇게 학습된 모델은 프롬프트를 통한 조작이 어렵고, 원하지 않는 상황에서 의도치 않은 출력을 만들 수도 있습니다. 반면, 라벨링과 함께 학습하면 특정 개념과 키워드를 연결하여 조정할 수 있기 때문에 다양한 프롬프트로 활용할 수 있는 유연한 모델이 됩니다.
LoRA 학습에서 라벨링은 필수적인 요소는 아니지만, 모델의 활용도를 높이고 원하는 결과를 얻기 위해 매우 중요한 과정입니다. 라벨링 없이 학습하면 특정 스타일이나 개체를 강하게 학습할 수 있지만, 활용성이 떨어질 수 있습니다. 반면, 적절한 라벨링과 함께 학습하면 텍스트 프롬프트를 통해 원하는 결과를 더 쉽게 얻을 수 있습니다.
2-3-6.라벨링 방법
LoRA 학습을 위한 라벨링 작업은 다음과 같습니다.
1.
이미지 준비: 학습할 이미지 데이터를 수집합니다. (지금까지 이미지를 준비 했습니다.)
2.
자동 라벨링 (AI 활용): AI 기반 캡셔닝 도구를 활용하여 자동으로 캡션을 생성할 수 있습니다. (예: Blip, Clip-Interrogator등의 모델을 활용하거나 ChatGPT나 Llama3.2등의 멀티모달 LLM등을 활용합니다.)
3.
수동 라벨링: 자동 생성된 캡션을 검토하고, 필요하면 직접 수정하거나 추가합니다.
4.
라벨 저장: 캡션을 .txt 파일로 저장하거나, JSON 형식으로 데이터셋을 구성합니다.
5.
LoRA 학습 진행: 캡셔닝이 완료된 데이터를 LoRA 모델 학습에 활용합니다.
Clip Interrogator
Clip Interrogator는 CLIP 모델과 BLIP(Bootstrapped Language-Image Pretraining) 모델을 결합하여 이미지에 대한 텍스트 설명을 자동으로 생성하는 도구입니다. 주어진 이미지를 분석하여 스타일, 개체, 분위기를 캡션으로 변환 합니다. 아래의 링크에서 Clipt Interrogator를 사용해 라벨링을 할 수 있습니다.

Blip
BLIP(Bootstrapped Language-Image Pretraining)는 Salesforce Research에서 개발한 이미지-텍스트 이해 모델로, 이미지 캡셔닝, 이미지-텍스트 매칭, 비전-언어 사전학습에 활용할 수 있습니다. 아래의 링크에서 Blip을 사용해서 라벨링을 할 수 있습니다.
https://replicate.com/salesforce/blip

BLIP과. CLIP Interrogator의 비교
비교 항목 | BLIP | CLIP Interrogator |
캡션 스타일 | 자연어 문장형 (예: “A cat sitting on a couch.”) | 키워드 중심 (예: “cat, couch, indoor, soft lighting”) |
텍스트 품질 | 더 자연스럽고 문맥을 이해함 | 주어진 이미지에서 중요한 특징만 강조 |
사용 목적 | 설명적인 캡션 생성 (LoRA 학습, 이미지 설명 자동화) | 태그 기반 캡셔닝 (LoRA 프롬프트 최적화) |
정확도 | 텍스트 표현이 자연스럽고 명확 | 스타일과 특징을 세밀하게 캡션화 |
LoRA 데이터 라벨링 | 일반적인 문장형 라벨링에 적합 | 프롬프트 최적화에 적합 |
ChateGPT를 이용한 라벨링
최신 버전의 ChatGPT는 멀티모달 모델이기 때문에 이미지 입력을 처리할 수 있습니다. ChatGPT와 채팅을 통해서 학습을 위한 라벨링을 진행할 수 있습니다.

2-3-7. Llama 3.2
별도의 커스텀한 캐릭터를 만들기 LoRA를 만들고 LoRA 학습을 위해서 매번 라벨링하는 작업은 반복작업 일 수 있습니다. 저는 오픈소스 멀티모달 LLM인 Llama 3.2를 활용해 라벨링을 하는 간단한 프로그램을 만들어서 라벨링 작업을 처리했습니다. UI는 Gradio로 아래와 같이 심플하게 만들었습니다.
로컬 위치

1. Single Image Processing (단일 이미지 처리)
•
Upload Image: 사용자가 학습할 이미지를 업로드하는 기능입니다.
•
Preview: 업로드한 이미지를 미리 볼 수 있습니다.
2. AI Analysis (AI 분석)
•
Analyze Image 버튼: 업로드된 이미지를 AI가 분석하고 자동으로 설명(캡션)을 생성합니다.
•
AI Analysis 결과 창: AI가 생성한 이미지 설명이 텍스트로 표시됩니다.
3. LoRA Keywords (LoRA 키워드)
•
LoRA 학습에서 특정한 키워드를 설정할 수 있는 입력창 입니다.
•
예를 들어, 특정 인물이나 스타일을 LoRA에 학습시키고 싶다면 해당 키워드를 입력합니다.
4. Replace Subject (대체 키워드 입력)
•
AI가 자동으로 생성한 설명에서 특정 개체를 다른 키워드로 변경 가능합니다.
•
예제에서는 "young Asian woman"을 "kys"로 변경합니다.
5. Modified Description (수정된 설명)
•
사용자가 수동으로 AI가 생성한 설명을 수정할 수 있는 공간입니다.
6. Save Path (저장 경로)
•
라벨링된 데이터를 저장할 폴더 경로를 설정하는 기능입니다.
7. Generate Text (텍스트 생성)
•
최종적으로 수정된 라벨을 저장하거나 새로운 설명을 생성하는 기능입니다.

또한 Batch Processing 탭에서는 Single Image탭에서 했던 라벨링을 바탕으로 경로에 있는 모든 이미지에 일괄 적용할 수 있도록 했습니다.
1. Batch Processing (배치 처리) 모드
•
Single Image 모드와 구분: 개별 이미지 라벨링이 아니라, 한 번에 여러 장의 이미지를 처리하는 모드입니다.
2. Image Folder Path (이미지 폴더 경로)
•
LoRA 학습을 위해 라벨링할 이미지들이 저장된 폴더 경로를 입력하는 곳입니다.
•
여기서는 "E:\\\\download\\\\img_for_lora\\\\yunseo_labeling" 폴더가 선택됩니다.
3. Description Length (캡션 길이)
•
자동 생성될 설명(캡션)의 길이를 조정하는 입력 필드입니다.
•
현재 설정값은 300자로, 일반적인 문장형 캡셔닝이 가능하도록 설정됩니다.
4. LoRA Keywords (LoRA 키워드)
•
특정한 키워드를 포함하도록 설정하는 입력 필드입니다.
•
예제에서는 "kys"라는 키워드가 입력되어 있습니다. → LoRA 모델이 해당 키워드를 중심으로 학습하도록 데이터셋을 구성할 수 있습니다.
5. Save Path (저장 경로)
•
생성된 라벨링 파일(.txt)들이 저장될 폴더 경로입니다.
6. Start Batch (배치 처리 시작) 버튼
•
한 번에 여러 개의 이미지에 대해 AI 캡셔닝 및 라벨링을 자동 수행합니다.
•
버튼을 클릭하면 지정된 폴더 내 모든 이미지가 AI 분석을 거쳐 자동 라벨링됩니다.
7. Batch Results (배치 결과)
•
오른쪽 창에는 자동 생성된 캡션 파일들이 저장된 결과 목록이 표시됩니다.
•
예제에서는 "test_kys_012.jpg", "test_kys_013.jpg" 등의 파일이 성공적으로 처리되었으며, 각각 "test_kys_012.txt", "test_kys_013.txt" 등의 라벨 파일이 저장됩니다.

위와 같은 과정을 거쳐서 아래와 같이 LoRA 학습을 위한 데이터셋을 준비했습니다. 총 35개의 이미지와 그 이미지의 쌍이 되는 35개의 텍스트파일로 구성 시켰습니다. 그리고 그 이미지들과 텍스트들을 text_kys.zip으로 압축 시켰습니다.

다음 섹션에서는 이 데이터셋을 가지고 추가 학습을 하는 것에 대해서 설명하도록 하겠습니다.