
FluxGym은 BlackForest Lab의 Flux 모델을 더욱 쉽게 추가 학습(튜닝)할 수 있도록 설계된 툴입니다. 이 도구는 모델 학습 과정에서의 반복적인 실험과 조정을 간소화하여, 사용자가 효율적으로 모델을 만들 수 있도록 도와줍니다. FluxGym의 저장소는 아래의 링크를 통해서 접근할 수 있습니다.
설치
FluxGym설치는 해당 저장소의 Readme를 참고하시면 됩니다.
FluxGym은 설치에 대해 다양한 편의를 제공하고 있습니다. Pinokio를 사용하거나 프로젝트를 다운로드받고 파이썬 가상환경을 셋팅하고 프로젝트에 관련된 파이썬 모듈들을 설치하기만 하면 됩니다. 또는 Docker를 사용하시면 됩니다. 여기서는 Window플랫폼에서 venv를 사용하고 있다고 가정하고 설명하도록 하겠습니다.
venv를 실행시키고 python app.py로 FluxGym을 실행합니다.
python -m venv env
env\Scripts\activate
python app.py
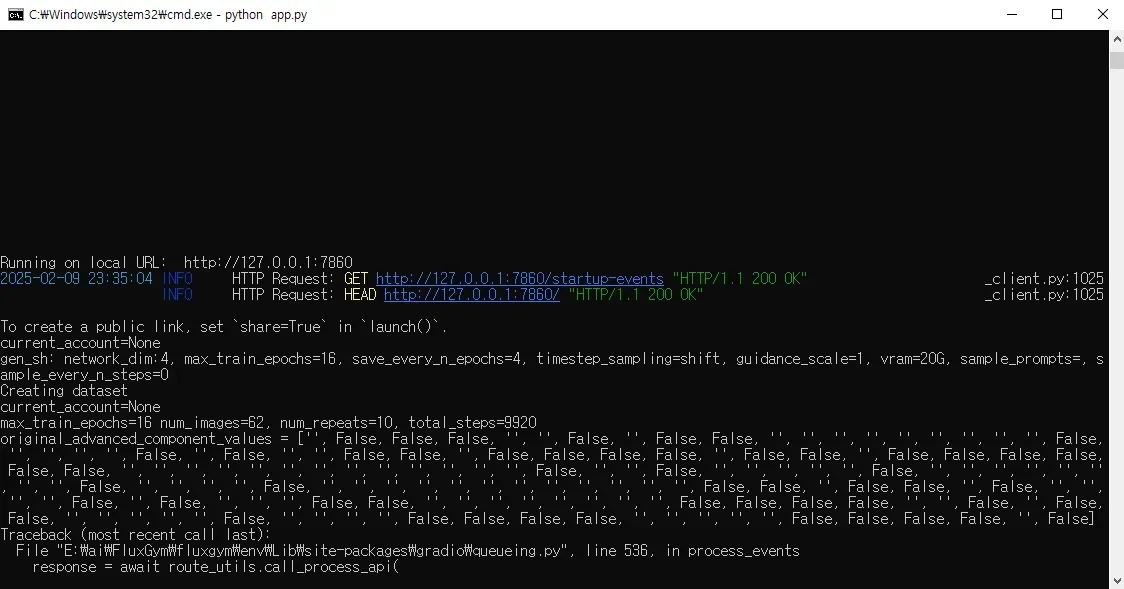
정상적으로 실행하면 아래와 같이 cmd에서 localhost:7860 포트를 통해서 연결된 브라우저로 바로 FluxGym 웹UI가 뜨는 것을 확인할 수 있습니다. 자동을 웹브라우저가 뜨지 않을 경우 위의 포트로 웹 브라우저에서 접근하면 됩니다.
Step 1. Lora Info
FluxGym의 UI는 아래와 같습니다.
•
The name of your LoRA (LoRA 이름 설정)
◦
학습할 LoRA 모델의 고유한 이름을 입력합니다.
◦
예제: flux_kys_lora
•
Trigger word/sentence (트리거 단어/문장)
◦
학습된 LoRA가 활성화될 때 사용할 단어나 문장을 설정합니다.
◦
예제: kys (이 단어가 포함된 프롬프트를 입력하면 LoRA가 활성화됩니다.)
•
Base model (기본 모델 선택)
◦
학습의 기반이 될 모델을 선택합니다.
◦
예제: flux-dev
◦
사용자가 models.yaml을 수정하여 추가 모델을 등록할 수 있습니다.
•
VRAM (사용할 GPU 메모리 선택)
◦
20G, 16G, 12G 중에서 선택 가능
◦
학습 시 사용할 VRAM 크기를 선택하여, GPU의 성능과 학습 가능성을 조정할 수 있습니다.
•
Repeat trains per image (이미지당 반복 학습 횟수)
◦
한 이미지가 반복 학습될 횟수를 설정합니다.
◦
예제: 5 → 각 이미지가 5번 반복하여 학습됩니다.
•
Max Train Epochs (최대 학습 에폭 수)
◦
전체 데이터셋을 몇 번 반복하여 학습할지 설정합니다.
◦
예제: 16 → 데이터셋 전체를 16회 반복 학습하게 했습니다(기본 설정입니다).
•
Expected training steps (예상되는 학습 스텝 수)
◦
예상되는 학습 스텝이 출력 됩니다. 이미지를 업로드하면 계산이 되어 출력 됩니다.
•
Sample Image Prompts (샘플 이미지 프롬프트)
◦
학습이 완료된 후 LoRA 모델을 테스트할 때 사용할 프롬프트 입니다.
◦
예제:
css
복사편집
a young Asian woman kys with white t-shirts and blue jean and posing on the beach.
Plain Text
복사
◦
이 문장을 프롬프트로 넣으면 학습된 LoRA 모델이 kys와 관련된 이미지를 생성할 수 있습니다.
•
Sample Image Every N Steps (N 스텝마다 샘플 이미지 생성 여부)
◦
0으로 설정됨 → 학습 중간에 샘플 이미지를 생성하지 않도록 했습니다.
•
Resize dataset images (데이터셋 이미지 크기 조정)
◦
데이터셋 이미지를 특정 크기로 리사이징 합니다.
◦
예제: 512 → 모든 학습 데이터셋의 이미지 크기를 768x768 픽셀로 셋팅했습니다. 보통 Flux에서는 학습이미지를 1024 x 1024사이즈의 이미지를 권장합니다. 하지만 Kling등의 비디오 모델에서 만들어진 영상들의 사이즈가 보통 720p였기 때문에 학습데이터를 만들기 위해서 1:1 비율로 크롭하면 해상도가 720 x 720 이었습니다. 해서 720픽셀 사이즈로 셋팅 했습니다.

Step 2. Dataset
준비한 학습용 데이터를 드래그&드롭으로 FluxGym에 업로드한 이미지 입니다. 만약에 라벨링(캡셔닝)이 없고 이미지만 있을 경우 FluxGym에서 Florence-2를 이용해서 캡셔닝을 생성할 수 있습니다.
Florence-2는 Microsoft의 비전-언어 모델(VLM, Vision-Language Model) 중 하나로, 이미지를 이해하고 텍스트로 설명하는 AI 모델입니다. OpenAI의 CLIP이나 Flamingo와 유사한 역할을 합니다. Florence-2는 단순한 캡션 생성 외에도 이미지 검색, 객체 인식, 설명 요약 등의 기능을 수행할 수 있습니다. FluxGym에서는 캡셔닝에 Florence-2를 채용하고 있습니다. 일단 캡셔닝을 이전에 준비 했기 때문에 그대로 사용하도록 하겠습니다.

FluxGym에는 다양한 옵션들이 있습니다. 하지만 여기에서는 지면상 다루지 않도록 하겠습니다.

Step 3. Train
스타트 트레이닝을 하면 아래와같이 트레이닝이 진행되면서 보여지는 로그를 확인할 수 있습니다.

훈련이 완료되면 FluxGym의 outputs 디렉토리에 LoRA파일이 출력된 것을 확인할 수 있습니다. flux-kys-lora-000004.safetensors, flux-kys-lora-000008.safetensors, flux-kys-lora-000012.safetensors 등의 파일이 생성되는 이유는 FluxGym에서 LoRA 모델 학습 진행 중 특정 Epoch 간격마다 체크포인트(Checkpoint)를 저장해서 생긴 파일들 입니다. 이 방식은 모델이 정상적으로 학습되고 있는지 확인하거나, 특정 Epoch에서 학습을 중단하고 결과를 평가하는 데 쓰일 수 있습니다. 마지막 flux-kys-lora.safetensors 파일은 최종적으로 저장된 모델입니다. 또한 16 Epoch 학습을 계획했지만 8 Epoch에서 원하는 품질을 얻었다면, 000008.safetensors 파일을 최종 결과물로 사용할 수도 있습니다. 즉, 이것은 학습이 불필요하게 오래 진행되지 않도록 최적의 Epoch을 찾아낼 수 있는 기능으로 인해서 만들어진 결과입니다.

dataset.toml 파일은 FluxGym에서 LoRA 학습에 사용할 데이터셋을 구성하는 설정 파일입니다. 이 파일을 통해 이미지 경로, 캡션 파일 확장자, 해상도, 배치 크기, 반복 횟수 등을 정의할 수 있습니다.. 트리거 단어(kys)를 중심으로 한 이미지-캡션 쌍을 사용하여 LoRA 모델을 훈련할 수 있도록 설계되어있고. 이 파일은 train.bat과 함께 사용되며, FluxGym의 학습 프로세스를 자동화할 수 있습니다. 그리고 UI에서 데이터셋을 업로드하고 학습을 진행하면 FluxGym의 dataset 디렉토리에 학습시킨 데이터셋들이 옮겨져있는 것을 확인할 수 있습니다. *.npz 파일은 numpy의 파일 포맷입니다.

import numpy as np
file_path = "E:\\ai\\FluxGym\\fluxgym\\datasets\\flux-kys-lora\\test_kys_001_0512x0512_flux.npz"
data = np.load(file_path)
data_keys = data.files
data_info = {key: data[key].shape for key in data_keys}
data_info
print(data_info)
{
'latents_64x64': (16, 64, 64),
'original_size_64x64': (2,),
'crop_ltrb_64x64': (4,)
}
이 .npz 파일에는 다음과 같은 정보가 포함되어 있습니다.
latents_64x64 → (16, 64, 64)
16개의 64x64 크기의 Latent 데이터 이 데이터는 VAE(Autoencoder)로 인코딩된 이미지의 잠재 공간 표현(latents) 입니다. Flux 모델의 학습 속도를 높이기 위해 이미지 대신 사용될 가능성이 큽니다.
original_size_64x64 → (2,)
원본 이미지의 크기를 나타내는 값(예: 720 x 720에서 64x64로 변환됨) 학습 중 원래 이미지의 해상도를 저장하는 메타데이터일 수 있습니다.
crop_ltrb_64x64 → (4,)
이미지의 Crop 영역을 나타내는 데이터 (Left, Top, Right, Bottom) 원본 이미지에서 잘린 부분의 좌표 정보를 포함하고 있을 수 있습니다.
ComfyUI에서의 추론 테스트
FluxGym에서 학습한 LoRA의 이름을 이전에 Fal.ai에서 학습시킨 LoRA와 구분하기 위해서 fluxgym-kys-lora.safetensors라고 변경했습니다. 그리고 ComfyUI Load LoRA 노드에서 해당 LoRA를 불러왔습니다.

아래의 이미지는 전체 워크플로우 입니다.

FluxGym에서 만든 LoRA를 이용해서 생성된 이미지 입니다.
