이미지 업스케일링 항상 겪는 문제는 특히 인물일 경우 인상이 변화한다는 점입니다. 아래에서 소개하고 있는 모델과 서비스는 그동안 사용한 업스케일러 중에서 그나마 인상의 변화가 상대적으로 적었습니다.
InvSR
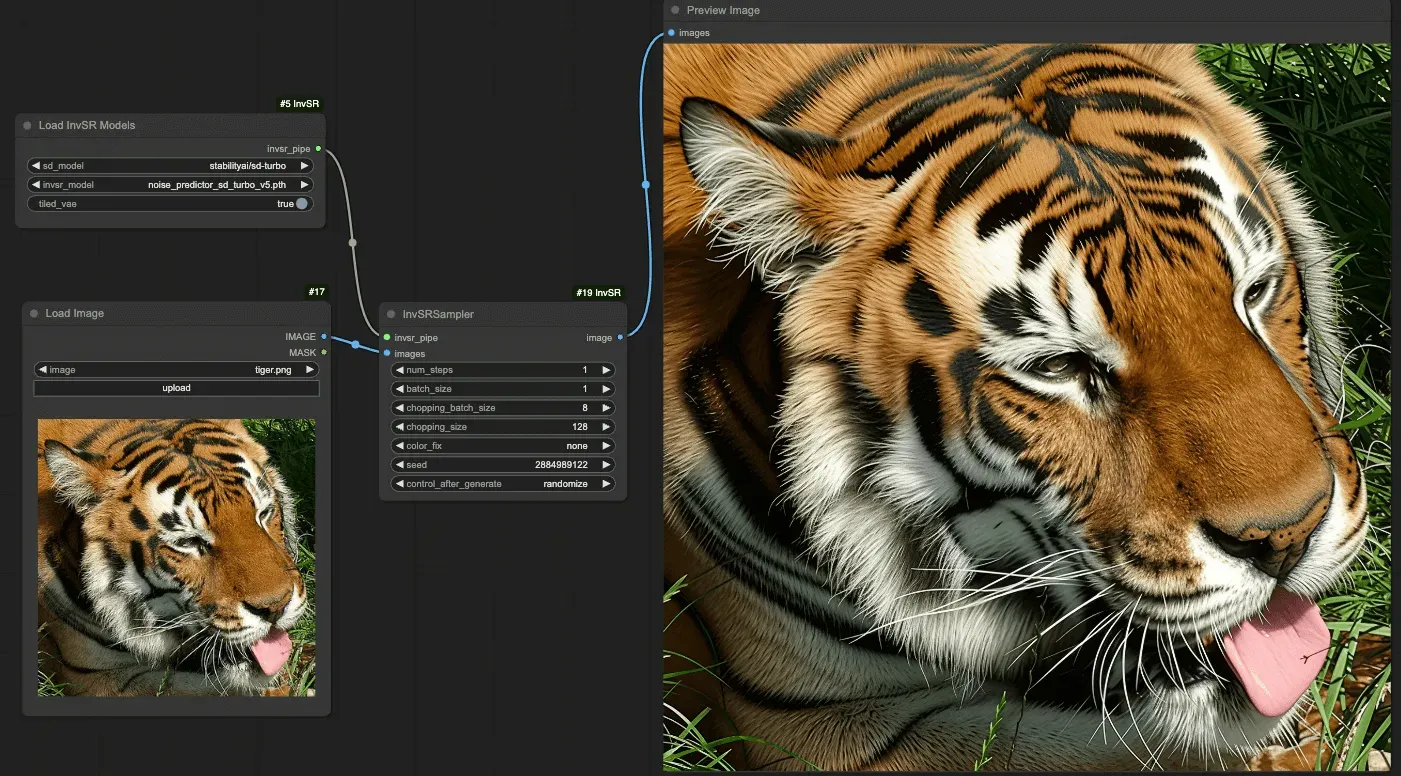
InvSR은 Diffusion Inversion을 이용한 이미지 초해상도(SR) 기술입니다. 부분적인 노이즈 예측(Partial Noise Prediction)을 통해 중간 상태를 구성하고 이를 시작점으로 삼아 샘플링을 진행합니다. 그리고 딥 노이즈 예측기를 활용해 최적의 노이즈 맵을 예측하고, 이를 바탕으로 샘플링을 초기화하여 고해상도 이미지를 생성합니다.
InvSR의 경우 ComfyUI, HuggingFace Space, Colab등에서 사용할 수 있습니다.

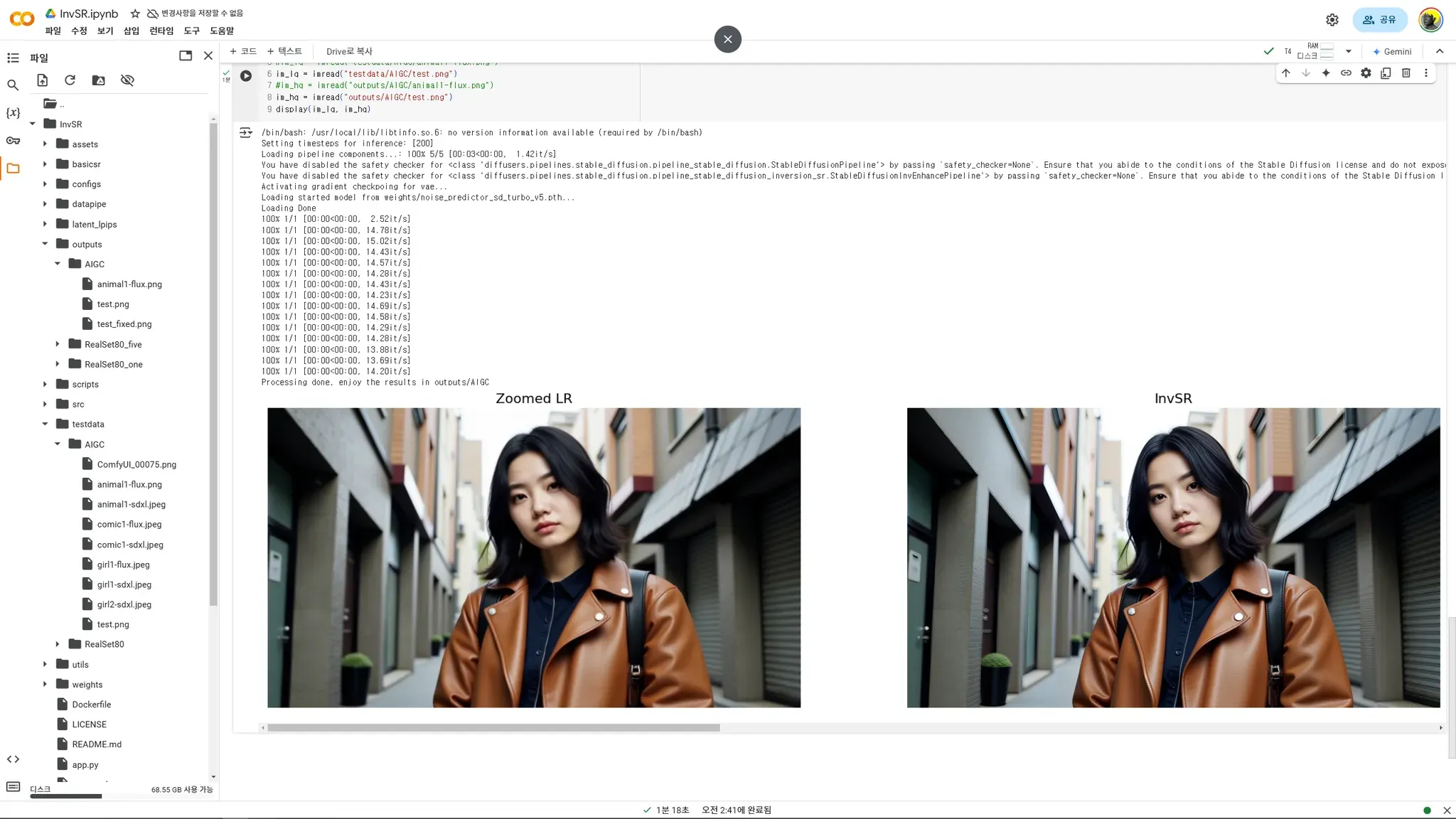
!python inference_invsr.py -i testdata/AIGC/test.png -o outputs/AIGC/ --chopping_size 128 --num_steps 1
im_lq = imread("testdata/AIGC/test.png")
im_hq = imread("outputs/AIGC/test.png")
display(im_lq, im_hq)
Plain Text
복사
•
* !python inference_invsr.py -i testdata/AIGC/ComfyUI_00078_.png -o outputs/AIGC/ --chopping_size 128 --num_steps 1 # 이 부분에 파일명을 인자로 넣어야지 스크립트가 작동합니다.
아래의 이미지는 1024 x 576 사이즈의 원본 이미지가 InsSR에 의해서 4096 x 2034 업스케일링 된 이미지입니다. 전반적으로 유사 하지만 모델에 의해서 디테일이 추가가 되면서 인상의 세부적인 부분들에 약간의 변화가 생겼습니다.

ClarityAI Upscale
최근에 Flux 기반으로 업스케일 하는 기능을 ClarityAI 에서 공개 했습니다.

ClarityAI의 경우 Creative, Cristal, Flux 세가지 종류의 업스케일을 지원하고 있습니다.

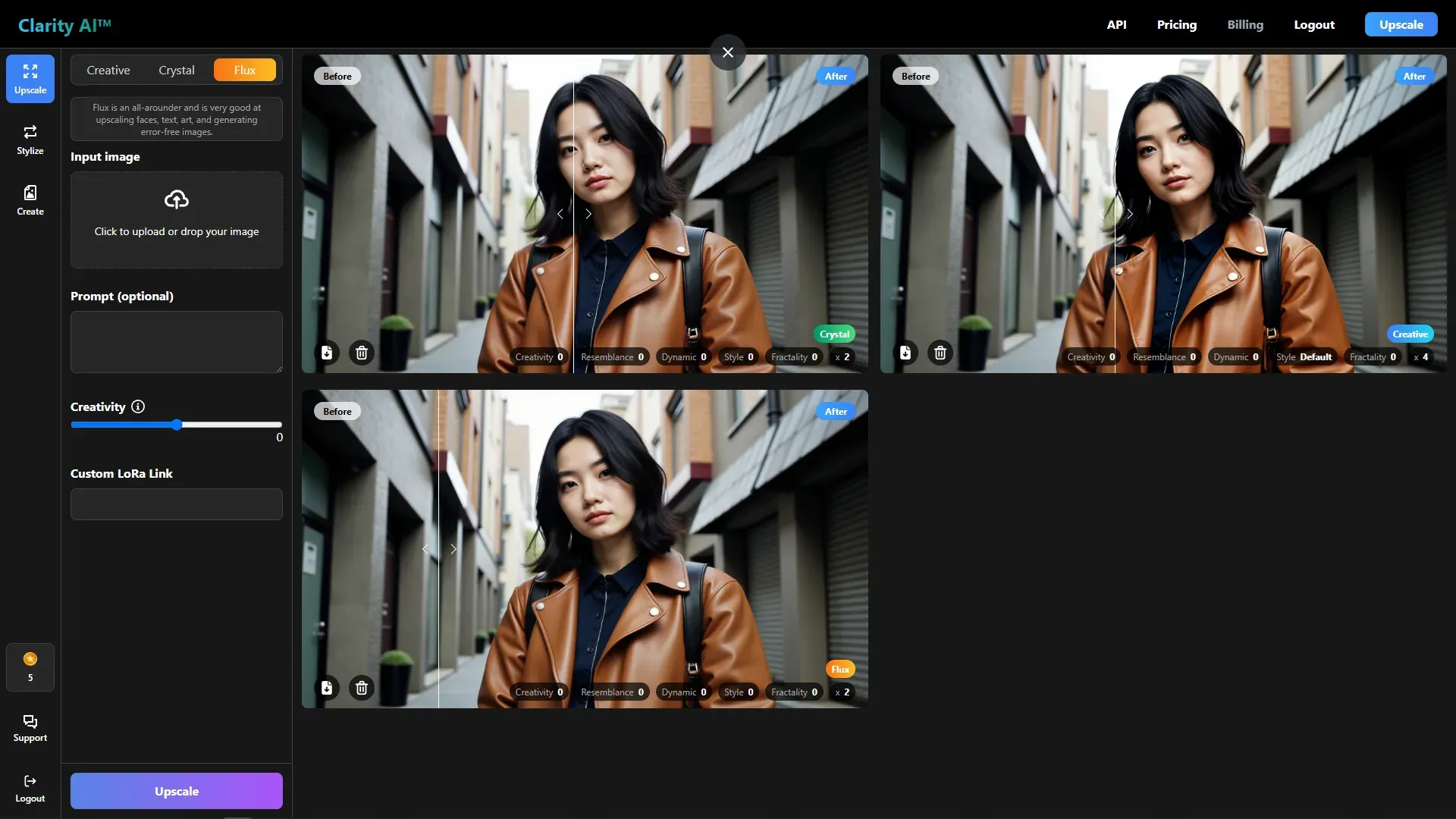
Flux 업스케일의 경우 아래와 같이 이미지를 업로드, 프롬프트, Creativity 슬라이더 그리고 Custom LoRA Link를 입력하는 텍스트 필드등의 옵션이 있습니다. 여기서 특이한 점은 Custom한 Flux LoRA링크를 입력할 수 있게 한다는 점입니다. 특별한 프롬프트나 Creavivity 슬라이더 조절 없이 Fal.ai에서 만든 LoRA의 링크만 입력해서 업스케일 하도록 하겠습니다.

Fal.ai의 LoRA 패스는 fal-ai/flux-lora-fast-training의 Train history에서 Diffusers Lora FIle을 Copy Link를 통해서 카피해서 입력하면 됩니다.

ClarityAI의 Flux Upsacle의 결과 입니다. 원본 이미지는 1024 x 576 픽셀 이었지만 에서 048 x 1152 픽셀로 인물의 아이덴티티를 유지하면서 업스케일 되었습니다.

아래는 ClarityAI의 Flux모델(LoRA)의 결과에 Crystal 모델을 적용한 이미지 입니다.






지금까지 Google DeppMind ImageFX에서 한장의 인물 사진을 얻어서 그 인물을 계속 생성하는, 일종의 캐릭터화 하는 작업을 해봤습니다. 최근 발전하고 있는 생성 AI 비디오 모델을 실험적으로 학습 데이터를 만드는데 활용해 봤습니다. 특히 KlingAI를 필두로 Image-to-Video시 캐릭터의 일관성이 훌륭해 졌습니다. 특히 요 몇 일간 Pixverse에서는 Turntable 같은 이펙트들이 공개가 되었는데 한 장의 이미지로 인물의 360도 영상 및 이미지를 얻을수 있게 된 것이 놀라웠습니다. 이는 3D 모델을 생성하기 위한 훌륭한 소스가 될 것으로 보입니다. 이 기술을 통해 한 장의 이미지에서 여러 각도를 추론하고, NeRF와 3D Gaussian같은 기술을 활용해 3D정보(포인트 클라우드, 3D 메쉬 및 텍스처)를 추출할 수 있게 될 것으로 보입니다.
일반적으로 추가 학습에는 합성 데이터 사용을 피하는 것이 좋지만, 실제 인물의 초상권과 프라이버시 문제를 고려해 이 책에서는 여러가지 모델로 만들어진 합성 데이터를 활용했습니다. 그러나 최근 생성 AI 모델들의 발전 덕분에 합성 데이터를 사용한 결과가 그리 나쁘지 않은 것 같습니다. 요즘은 오히려 더 커스터마이징 할 수 있어서 전에 없이 더 다양하게 활용될 수 있을 것 같습니다. 또한 InvSR이나 ClarityAI같은 Diffusion 베이스의 아이덴티티를 유지하면서 업스케일 하는 기술들이 계속 새롭게 연구되고 발전하고 있어서 앞으로 더 큰 이미지와 영상을 만들어갈 수 있을 것으로 보입니다.
지금 까지 생성된 이미지 일부를 KlingAI(1.6)의 Image-to-Video로 영상화 했습니다.
아래의 영상은 Veo2로 생성한 영상들을 합친 영상입니다.