
fal.ai는 개발자를 위한 생성 미디어 플랫폼으로, 고성능 AI 모델 추론 및 훈련 기능을 제공합니다. 이 플랫폼은 특히 이미지 생성 분야에서 Flux API를 통해 최적화된 추론 엔진을 제공하며, 이를 통해 개발자들은 고품질의 생성 미디어 모델에 접근할 수 있습니다.
아래의 링크를 통해서 Flux용 LoRA를 간편하고 빠르게 학습시킬 수 있습니다.
아래의 이미지는 Fal.ai에서 제공하고 있는 flux-lora-fast-training의 인터페이스 입니다. 저의 경우 이미 여러번 학습을 시켜서 Training history에 학습을 시킨 기록이 여럿 있습니다.
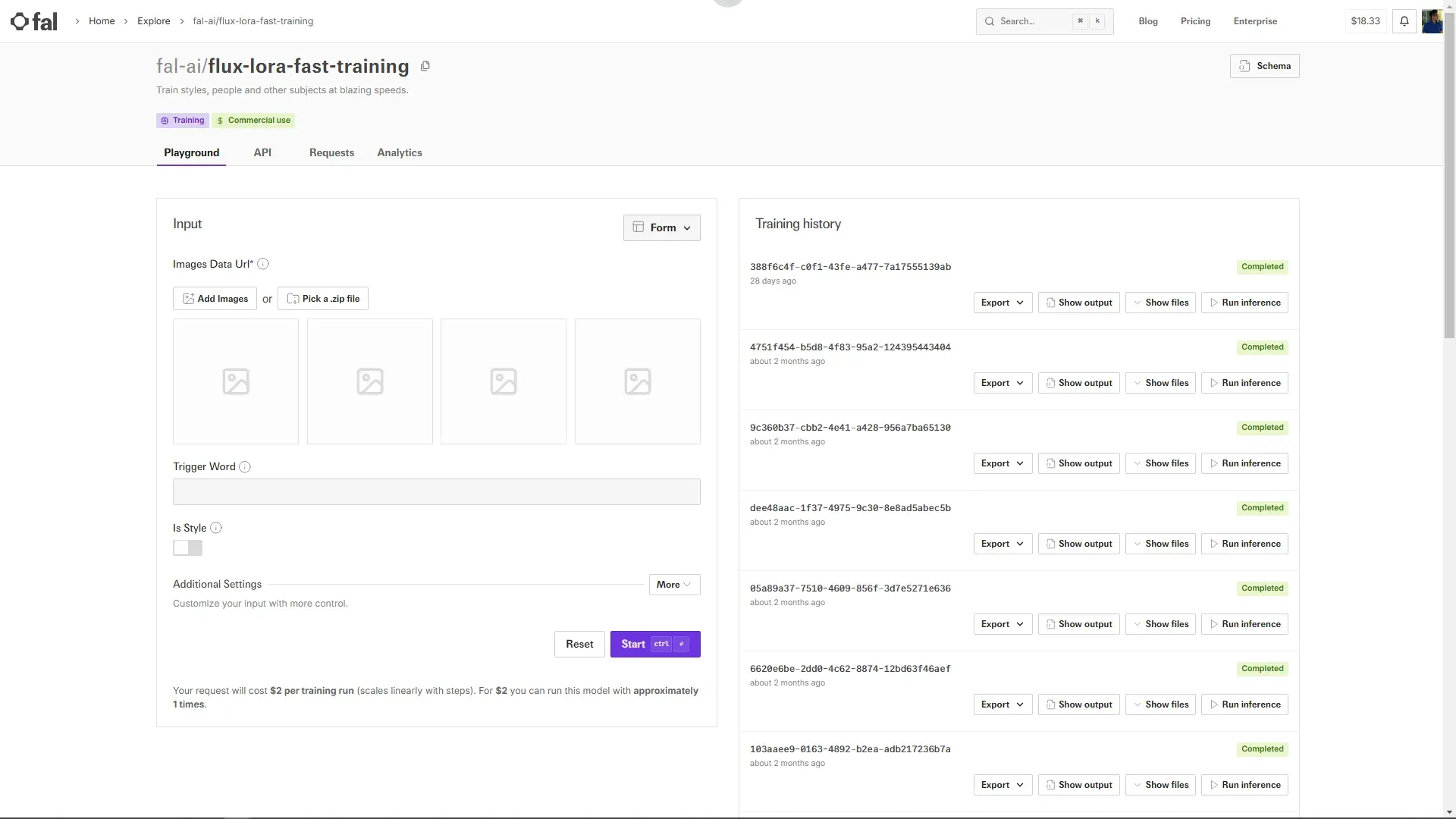
1. Images Data URL
•
이미지를 업로드하는 필수 입력란입니다.
•
사용자는 Add Images 버튼을 눌러 개별 이미지를 추가하거나, Pick a .zip file을 선택해 압축된 이미지 파일을 업로드할 수 있습니다.
2. Trigger Word
•
특정 트리거 단어를 입력하는 필드입니다.
•
이 단어는 훈련된 모델이 특정 패턴을 학습하거나, 특정 스타일을 생성하기 위해서 필요합니다.
3. Is Style
•
스타일 학습을 활성화하는 기능입니다. 여기서는 스타일이 아니라 구체적인 인물이기 때문에 비활성화 합니다.
4. Additional Settings (추가 설정)
•
Create Masks: 활성화된 상태(보라색)로, 모델이 이미지에서 마스크(특정 부분을 강조하는 영역)를 생성하도록 설정하는 기능입니다. 이 기능을 사용하면 AI 모델이 학습 시 중요 객체(특히 사람의 얼굴)를 더 정밀하게 분석하고 훈련할 수 있도록 도와줍니다. 기본적으로 활성화 되어 있습니다. 특히 인물 중심의 AI 모델 을 훈련할 때 유용하며, 보다 세밀한 학습이 가능해집니다.
•
Steps: 슬라이더와 직접 입력란을 통해 조정할 수 있으며, 기본값은 1000으로 설정되어 있습니다.
◦
이 값은 모델의 훈련 단계(steps)를 조정하며, 높을수록 훈련 시간이 길어지고 정확도가 증가하지만 너무 높을경우 오버피팅이 생깁니다.
•
Is Input Format Already Preprocessed: 체크박스로, 데이터가 이미 전처리된 상태인지 여부를 설정하는 옵션입니다. 이 옵션은 사용자의 입력 데이터가 모델 학습을 위해 미리 준비되었는지 확인하는 설정으로 기본값(False) 상태에서는 원본 데이터를 업로드하면 시스템이 자동으로 매칭 및 변환을 수행합니다. True로 설정하면, 사용자가 미리 준비한 전처리된 데이터가 그대로 사용됩니다. 따라서, 전처리 여부에 따라 이 옵션을 적절히 설정해야 모델이 정상적으로 학습할 수 있습니다.
•
Data Archive Format: 특정한 데이터 형식을 입력할 수 있는 필드로, 압축 형식 등을 정의하는 데 사용될 수 있습니다.
5. 비용 안내
•
현재 설정 기준으로 훈련 비용이 $2 per training run이며, 설정에 따라 비용이 증가할 수 있습니다.
•
사용자는 $2로 약 1회 훈련을 실행할 수 있음을 안내하고 있습니다.
6. 실행 버튼
•
Reset: 설정을 초기화하는 버튼
•
Start: CTRL + Enter 단축키로 실행할 수 있으며, 훈련을 시작하는 버튼입니다.

앞의 섹션에서 준비한 데이터셋 파일(test_kys.zip)을 Input에 입력합니다. Trigger Word는 유니크해야 하기 때문에 저는 kys로 입력했습니다. 나머지 설정은 기본 설정 그대로 사용했습니다.

트레이닝을 시작하면 아래의 이미지와 같이 로그를 확인할 수 있습니다.

정상적으로 훈련을 마치면 아래와 같이 Completed라는 메시지를 확인할 수 있습니다.

Show Files를 클릭하면 Config FIle과 Diffusers Lora FIle이 생성된 것을 확인할 수 있습니다. Download해서 ComfyUI에서 사용할 수 있는데 먼저 Fal.ai에서 제대로 생성이 되는지 추론을 시켜서 테스트 해보도록 하겠습니다. Run inference 버튼을 눌러서 추론을 시키도록 하겠습니다.

Run inference 버튼을 누르면 fal-ai/flux-lora 페이지로 이동을 합니다. Text to Image와 Image to Image를 지원하지만 여기서 필요한 것은 Text to Image 입니다. 기본적으로 prompt에는 트리거 워드가 입력되어있습니다. 여기서는 kys로 입력이 되어 있습니다. 이대로 추론을 시켜보도록 하겠습니다.

앞의 섹션에서 ImageFX를 통해서 만든 인물과 닮았지만 다른 의상과 다른 장소 그리고 다른 헤어 스타일을 가진 인물이 생성되는 것을 확인할 수 있습니다.

다시 한 번 더 추론 시켜서 얻은 이미지 입니다. 전혀 다른 배경에 다른 스타일을 한 닮은 인물이 두 명 추론이 되었습니다.


프롬프트로 제어해보도록 하겠습니다.


Fal.ai에서 추론 시킬 때 제공하는 추가적인 옵션은 아래와 같습니다.

Additional Settings를 보면 Image Size, Seed, Guidance Scale, Sync Mode, Num Images 그리고 Enable Safety Checker등의 옵션들을 확인할 수 있습니다.
1. Image Size (이미지 크기)
•
생성할 이미지의 크기를 설정하는 옵션입니다.
•
현재 Landscape 16:9(1024 × 576)로 설정되어 있으며, 사용자는 드롭다운 메뉴에서 다른 비율을 선택할 수 있습니다.
2. Num Inference Steps (추론 단계)
•
AI가 이미지를 생성할 때 몇 번의 반복 연산을 수행할지 결정하는 값입니다.
•
값이 클수록 이미지의 품질이 높아지지만, 생성 시간이 길어집니다.
•
현재 28단계로 설정되어 있습니다.
3. Seed (시드 값)
•
이미지 생성을 위한 난수(seed) 값입니다.
•
random으로 설정되어 있으며, 사용자가 특정 값을 입력하면 같은 설정에서 동일한 이미지를 재생성할 수 있습니다.
•
 (새로고침) 버튼을 눌러 랜덤 시드를 변경할 수 있습니다.
(새로고침) 버튼을 눌러 랜덤 시드를 변경할 수 있습니다.4. Guidance Scale (CFG, 컨디셔닝 강도)
•
프롬프트(prompt)를 얼마나 강하게 반영할지를 조정하는 값입니다.
•
값이 높을수록 프롬프트를 더욱 엄격하게 따라가지만, 지나치게 높으면 이미지가 부자연스러워질 수 있습니다.
•
현재 값은 3.5로 설정되어 있으며, 보통 7~10 정도가 일반적인 설정입니다.
5. Sync Mode
•
비동기/동기 모드 선택
•
활성화 시(true), 생성된 미디어가 Base64 URI 형식으로 반환되며, 이 데이터는 요청 기록(request history)에 저장되지 않습니다.
•
현재는 비활성화(기본 설정) 상태입니다.
6. Num Images (생성 이미지 개수)
•
한 번의 실행에서 몇 개의 이미지를 생성할지 설정하는 옵션입니다.
•
현재 1개의 이미지를 생성하도록 설정되어 있습니다.
7. Enable Safety Checker (안전 필터)
•
안전 검사를 활성화하는 옵션입니다.
•
기본적으로 활성화(true) 상태이며, 플레이그라운드에서는 비활성화할 수 없음 (API를 통해서만 변경 가능합니다).8. Output Format (출력 형식)
•
생성된 이미지의 출력 형식을 선택하는 옵션입니다.
•
현재 아무 형식도 선택되지 않았으며, 사용자가 Select the Output Format 버튼을 눌러 선택해야 합니다.
의도한 대로 Flux용 LoRA가 만들어진 것 같습니다. ComfyUI에서 Flux와 써보기 전에 Fal.ai에서 테스트 삼아서 몇 번 더 추론 시켜서 추가 학습이 잘 이루어 졌는지 확인해 보겠습니다.








