
갤러리 보기
Search
Tutorials
갤러리 보기
Search

최근 AI 기술의 발전은 비디오 콘텐츠 제작의 방식을 혁신적으로 변화시키고 있습니다. 과거에는 전문적인 장비와 많은 시간이 필요했던 영상 제작 과정이, 이제는 텍스트나 이미지와 같은 간단한 입력만으로도 가능 해졌습니다. 특히, 텍스트를 기반으로 영상을 생성하는 T2V(Text-to-Video), 이미지를 비디오로 변환시키는 I2V (Image-to-Video) 그리고 영상을 다른 스타일로 변환 시켜주는 V2V (Video-to-Video)기술은 콘텐츠 제작의 접근성을 대폭 확대하며, 창의적 작업의 새로운 가능성을 열어주고 있습니다.
생성 AI 비디오 모델은 단순히 사용자 경험을 향상시키는 데 그치지 않고, 마케팅, 교육, 엔터테인먼트 등 다양한 분야에서 혁신적인 도구로 자리 잡고 있습니다. 이 기술을 통해 사용자는 자신의 아이디어를 더 빠르고 직관적으로 시각화 할 수 있으며, 기존의 비디오 제작 과정에서 발생하는 시간과 비용을 절감할 수 있습니다.
이 글에서는 현재 가장 대표적인 생성형 AI 영상 플랫폼들 OpenAI의 Sora, KuaiShou의 Kling AI, RunwayML의 Gen-3, LumaAI의 Dream Machine(Ray2)그리고 최근 API통해서 공개된 Google DeepMind의 Veo2를 중심으로 설명을 하도록 하겠습니다.
1-1. T2V (Text-to-Video) 텍스트 입력으로 비디오를 생성
Text-to-Video 기술은 자연어 설명을 기반으로 동영상을 생성하는 기술입니다. 2025년 현재, 이 분야는 Google, Meta등의 거대 테크기업과 OpenAI등의 스타트업들에 의해서 활발한 연구와 발전이 이루어지고 있습니다. 이 기술은 대규모 언어 모델(LLM)과 생성형 AI를 결합하여 작동합니다. 텍스트 입력을 분석하여 장면의 구성 요소, 움직임, 시각적 특성 등을 파악하고, 이를 바탕으로 연속된 프레임을 생성합니다.
OpenAI Sora, KuaiShou의 Kling AI, RunwayML의 Gen-3, LumaAI의 Dream Machine(Ray2) 그리고 Google DeepMind의 Veo2 등 주요 생성형 AI 영상 플랫폼은 텍스트, 이미지 그리고 영상을 기반으로 AI 영상을 생성하며, 사용자 친화적인 UI를 제공합니다. 그중 Text-to-Video는 사용자가 간단한 텍스트 프롬프트를 입력하여 장면, 스타일, 색감 등을 설정할 수 있으며, 각 플랫폼의 모델은 이를 분석해 시각적 표현을 구현합니다. 또한 비율, 해상도, 길이 및 여러가지 옵션 기능들로 다양한 출력과 결과물 수정 및 확장 기능을 지원해 사용자가 원하는 결과를 쉽게 얻을 수 있게 합니다. 이러한 플랫폼들의 공통점은 쉬운 접근성과 효율성을 중심으로 하여 비전문가도 얼마든지 쉽게 창의적인 비디오 제작이 가능하도록 돕는 데 초점을 맞추고 있습니다.
1-1-1 각 플랫폼의 Text-to-Video UI
OpenAI Sora
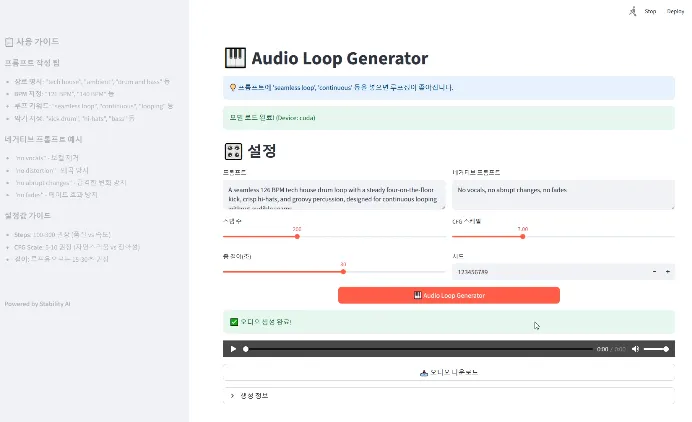
Sora의 사이트 주소는 https://sora.com/ 입니다. 사용하기 위해서는 가입과 플랜을 선택해서 구동이 필요한데 이런 부분들이 기초적인 것이기 때문에 여기서는 굳이 설명하지 않도록 하겠습니다. 나머지 플랫폼에 대해서도 설명을 생략하도록 하겠습니다. 가입과 플랜을 선택하면 아래와 같은 화면을 볼 수 있습니다.
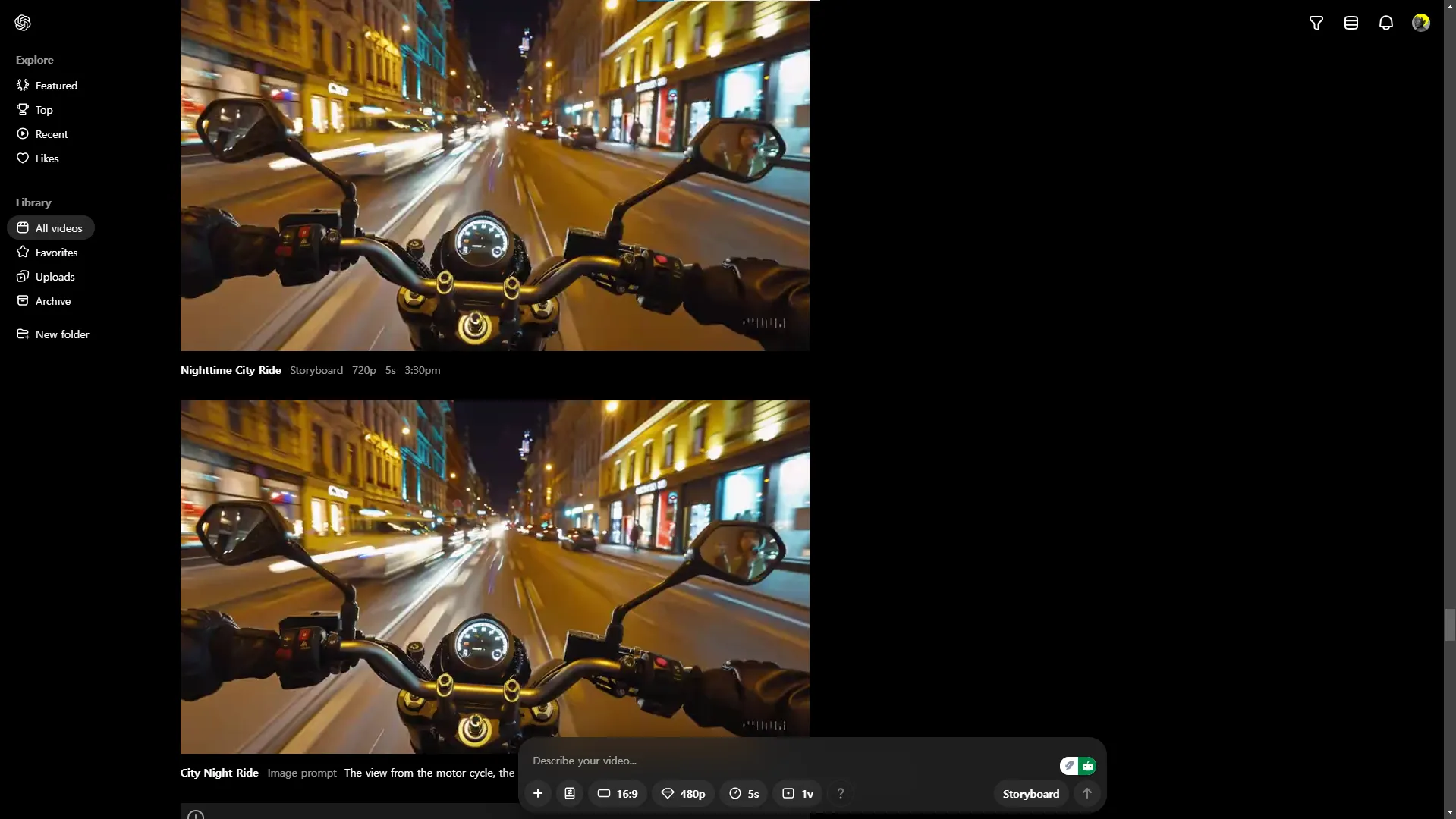
1-1. 비디오 생성 AI 모델과 서비스에 대한 설명



I2V(Image-to-Video) 기술은 한 장의 이미지를 움직이는 영상으로 만들어 주는 강력한 생성형 AI 기술입니다. 하지만 ‘어떤 이미지를 입력으로 사용하느냐’에 따라 결과물의 스타일과 품질이 크게 달라질 수 있습니다. 따라서 I2V를 활용해 영상을 만들고자 할 때는 먼저 원하는 장면과 캐릭터, 분위기에 최적화된 이미지를 준비하는 과정이 필요합니다. 아래에서는 대표적으로 사용되는 이미지 생성 모델들과 원하는 이미지를 생성하기 위해서 간단히 오픈소스 이미지 모델을 추가 학습 하는 방법들을 소개하도록 하겠습니다.
2-1-1. MidJourney 웹 인터페이스 개요
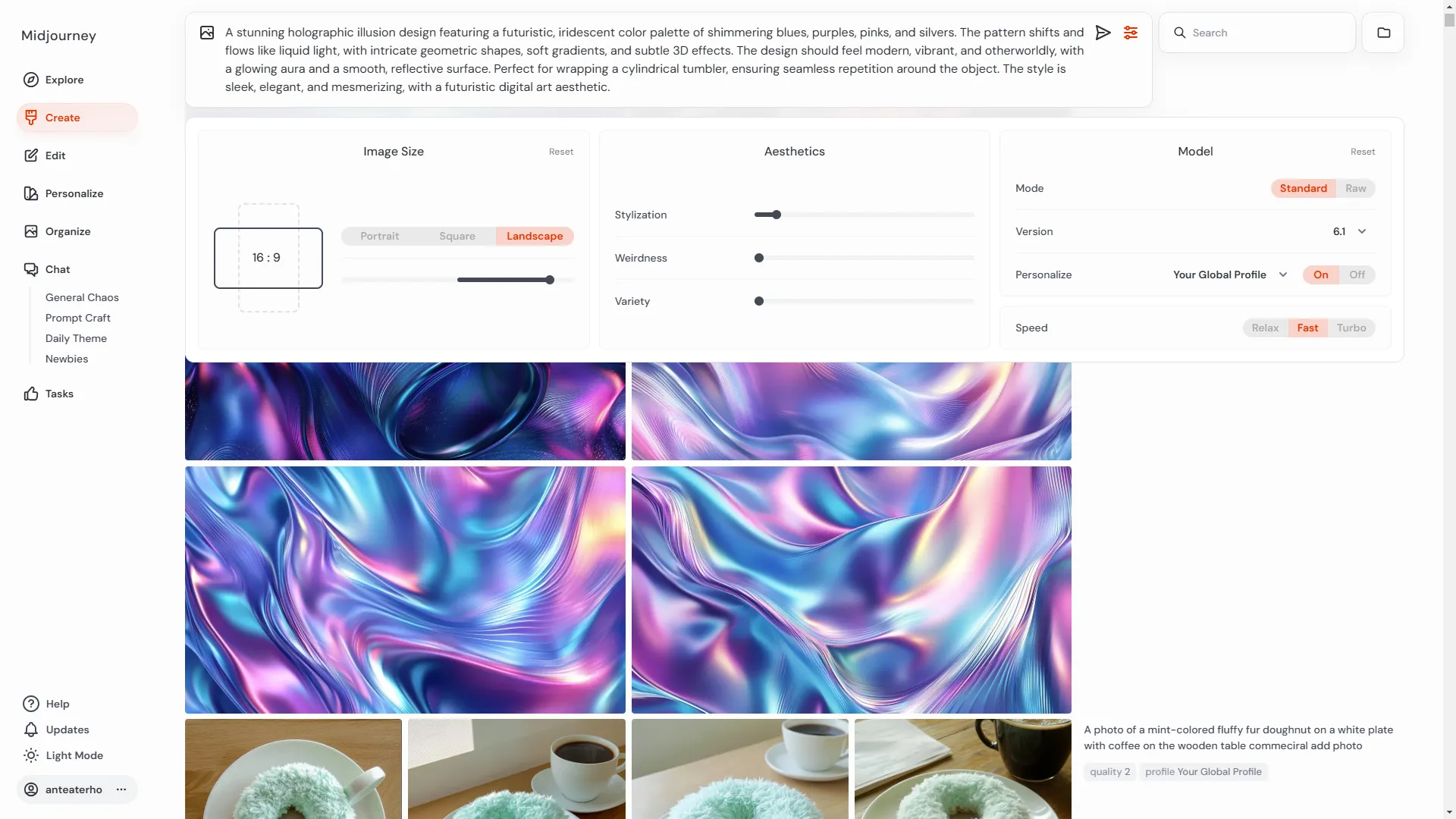
미드저니 AI 기반 이미지 생성 플랫폼으로, 사용자가 입력한 텍스트 프롬프트를 기반으로 독창적인 아트워크, 일러스트, 사진 스타일의 이미지를 생성하는 서비스입니다. 그동안은 주로 Discord에서 봇에 명령 입력해 이미지를 생성해왔지만, 최근에는 웹 인터페이스를 지원하여 아티스트가 보다 직관적인 환경에서 작업할 수 있게 되었습니다.
사이트는 주소는 https://www.midjourney.com 입다. Discord 계정이나 Google 계정을 연동해야 로그인 할 수 있습니다. 로그인 과정과 플랜을 선택하는 부분은 다른 플랫폼을 설명하는 것과 마찬가지로 생략하도록 하겠습니다.
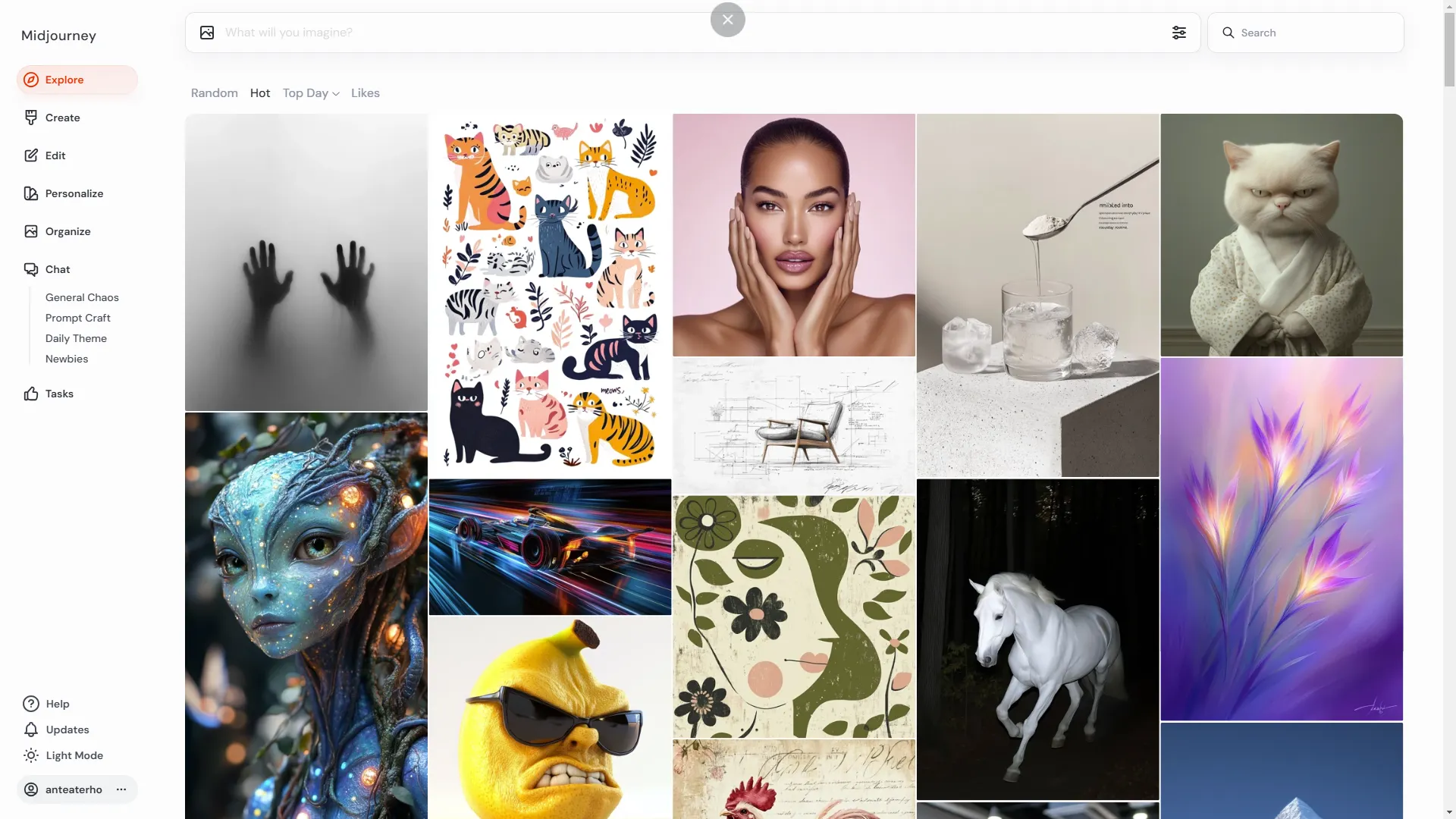
탐색
다른 사용자가 만든 인기 있는 이미지를 볼 수 있는 갤러리 입니다. 유저들이 생성한 다양한 스타일과 장르의 이미지들을 탐색할 수 있습니다. 처음에 시작할 때 다른사람들의 프롬프트를 참고하면 많은 도움이 됩니다.
생성(Create)
사용자가 직접 프롬프트를 입력하여 새로운 이미지를 생성하는 미드저니의 주된 기능입니다. 다양한 프롬프트를 입력하면서 다양한 옵션을 직관적으로 적용할 수 있습니다.
편집(Edit)
생성한 이미지를 지우거나 비율을 바꾸고 여백을 채우는 기능들이 있습니다. 또한 리텍스쳐(Retexture)라는 기존 이미지의 스타일을 변경하거나, 새로운 재질(Texture)을 적용하여 더욱 창의적인 아트워크를 만드는 기능도 있습니다. 리텍스쳐를 활성화 하려면 아래와 같은 조건이 충족되어야 합니다. (향후 이런 조건들은 해제 될 것 같습니다.)
2-1. Imag-to-Video(I2V)를 위한 이미지 생성 작업하기

2-2-1. Flux에 대해서
Black Forest Labs에서 개발한 FLUX는 텍스트를 기반으로 이미지를 생성하는 최첨단 모델입니다. 이 모델은 자연어 설명을 입력 받아 해당하는 이미지를 생성하는 능력을 갖추고 있습니다. Flux가 공개된 이후로 Stable Diffusion보다 Flux를 더 많이 사용하고 있습니다. Stable Diffusion은 오픈소스 AI 생성 모델로 강력한 커뮤니티와 확장성을 가지고 있지만, 속도, 품질, 모델 최적화 측면에서 Flux가 더 뛰어난 성능을 제공하고 있기 때문입니다. 하지만 AI 이미지 생성 기술이 급격하게 발전하면서 AI 영상 작업에 대한 요구가 늘어나고 있어서 사용빈도는 생성 AI 비디오 모델을 더 많이 사용하고 있습니다. 하지만 AI 영상을 만들기 위해서는 이미지 프롬프팅이 가장 효과적이고 빠르게 작업하 때는 Midjourney를 사용하고 있지만 디테일한 커스터마이징이 필요하거나 개발이 필요한 작업은 Flux를 여전히 사용하고 있습니다.
FLUX 모델은 다양한 버전으로 제공되며, 각 버전은 다음과 같은 특징을 가지고 있습니다:
•
FLUX.1 [pro]: 최고 수준의 성능을 제공하며, 우수한 프롬프트 추종 능력, 시각적 품질, 이미지 디테일 및 출력 다양성을 갖추고 있습니다. 이 버전은 API를 통해 접근할 수 있으며, Freepik, Together.ai, Fal.ai, Replicate 등의 파트너를 통해서도 이용 가능합니다.
•
FLUX.1 [dev]: FLUX.1 [pro]에서 직접 증류된 오픈 웨이트 모델로, 비상업적 용도로 사용됩니다. 유사한 품질과 프롬프트 추종 능력을 가지며, 동일한 크기의 표준 모델보다 효율적입니다. 이 버전의 웨이트는 Hugging Face에서 제공되며, Replicate, Fal.ai, Mystic, Deepinfra, TensorOpera, Hyperbolic 등을 통해 직접 사용해볼 수 있습니다.
•
FLUX.1 [schnell]: 가장 빠른 모델로, 로컬 개발 및 개인 사용을 위해 최적화되었습니다. Apache 2.0 라이선스 하에 공개되어 있으며, Hugging Face에서 웨이트를 제공하고 GitHub에서 추론 코드를 찾을 수 있습니다. Replicate, Fal.ai, Mystic, Deepinfra, TensorOpera, Together.ai 등을 통해서도 이용 가능합니다.
또한, FLUX.1 Tools라는 도구 모음이 제공되어, 기본 텍스트-이미지 모델인 FLUX.1에 제어 및 조정 기능을 추가합니다. 이 도구에는 다음과 같은 기능이 포함됩니다:
•
FLUX.1 Fill: 텍스트 설명과 이진 마스크를 사용하여 실제 및 생성된 이미지를 편집하고 확장할 수 있는 최첨단 인페인팅 및 아웃페인팅 모델입니다.
•
FLUX.1 Depth: 입력 이미지에서 추출한 깊이 맵과 텍스트 프롬프트를 기반으로 구조적 지도를 가능하게 하는 모델입니다.
•
FLUX.1 Canny: 입력 이미지에서 추출한 캐니 에지와 텍스트 프롬프트를 기반으로 구조적 지도를 가능하게 하는 모델입니다.
•
FLUX.1 Redux: 입력 이미지와 텍스트 프롬프트를 혼합하여 새로운 버전을 생성할 수 있는 어댑터입니다.
이러한 도구들은 FLUX.1 [dev] 모델 시리즈의 오픈 액세스 모델로 제공되며, BFL API를 통해 FLUX.1 [pro]와 함께 사용할 수 있습니다.
BFL API는 Black Forest Labs에서 제공하는 개발자용 인터페이스로, 최첨단 이미지 생성 모델인 FLUX의 기능을 애플리케이션이나 서비스에 통합할 수 있도록 지원합니다.
2-2. Flux에서 이미지 생성하기



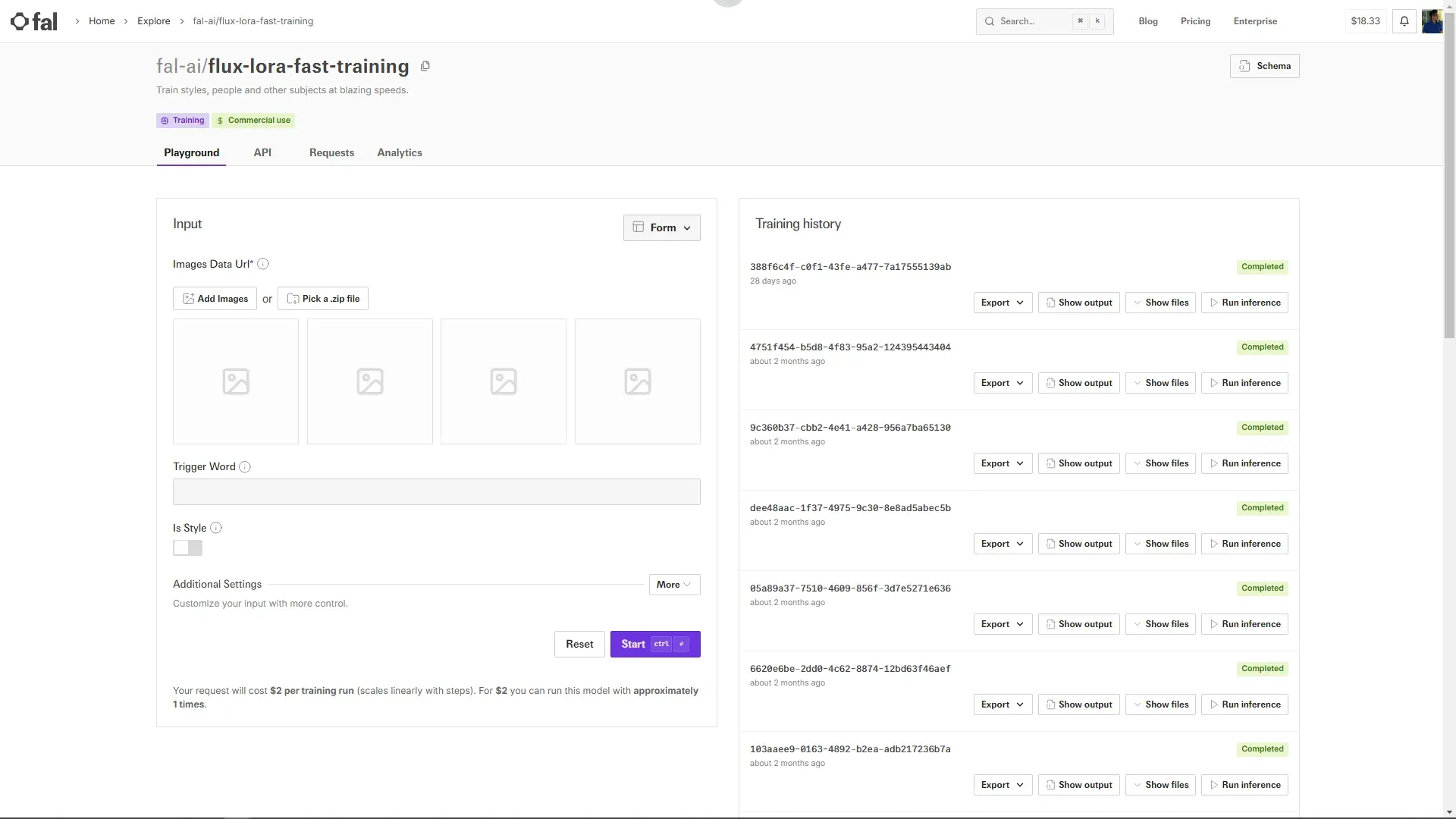

Fal.ai에서 트레이닝 시킨 LoRA파일을 다운받아 ComfyUI의 LoRA 디렉토리에 위치 시킵니다. 저의 경우 flux폴더를 따로 만들어서 관리하고 있습니다.
ComfyUI_windows_portable\ComfyUI\models\loras\flux
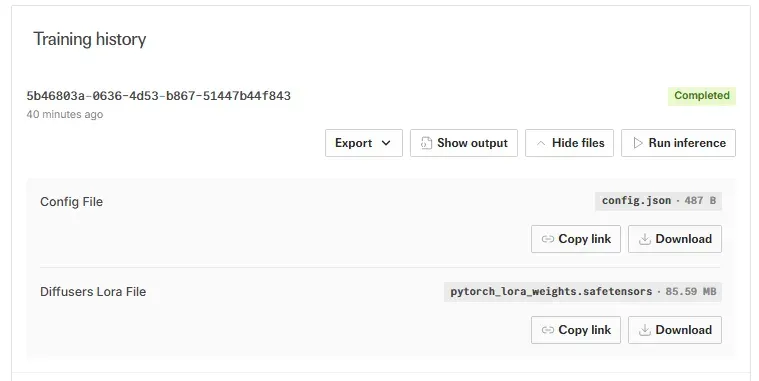
ComfyUI을 실행시키도록 합니다. ComfyUI의 설치는 챕터 "2-2. Flux에서의 이미지 생성"을 참고하거나 공식 문서를 확인해서 설치하면 됩니다.
ComfyUI는 최근에 인스톨러가 제공되고 있습니다. 아래의 링크에서 다운로드 받을 수 있습니다.
https://www.comfy.org/download
이전 섹션 2-2-2에서 사용했던 ComfyUI 워크플로우에서 Load LoRA노드에서 Fal.ai에서 학습시킨 LoRA를 선택 했습니다. Fal.ai에서 생성한 LoRA의 이름을 flux_kys_lora.safetensors라고 알기 쉽게 이름을 교체 했습니다.
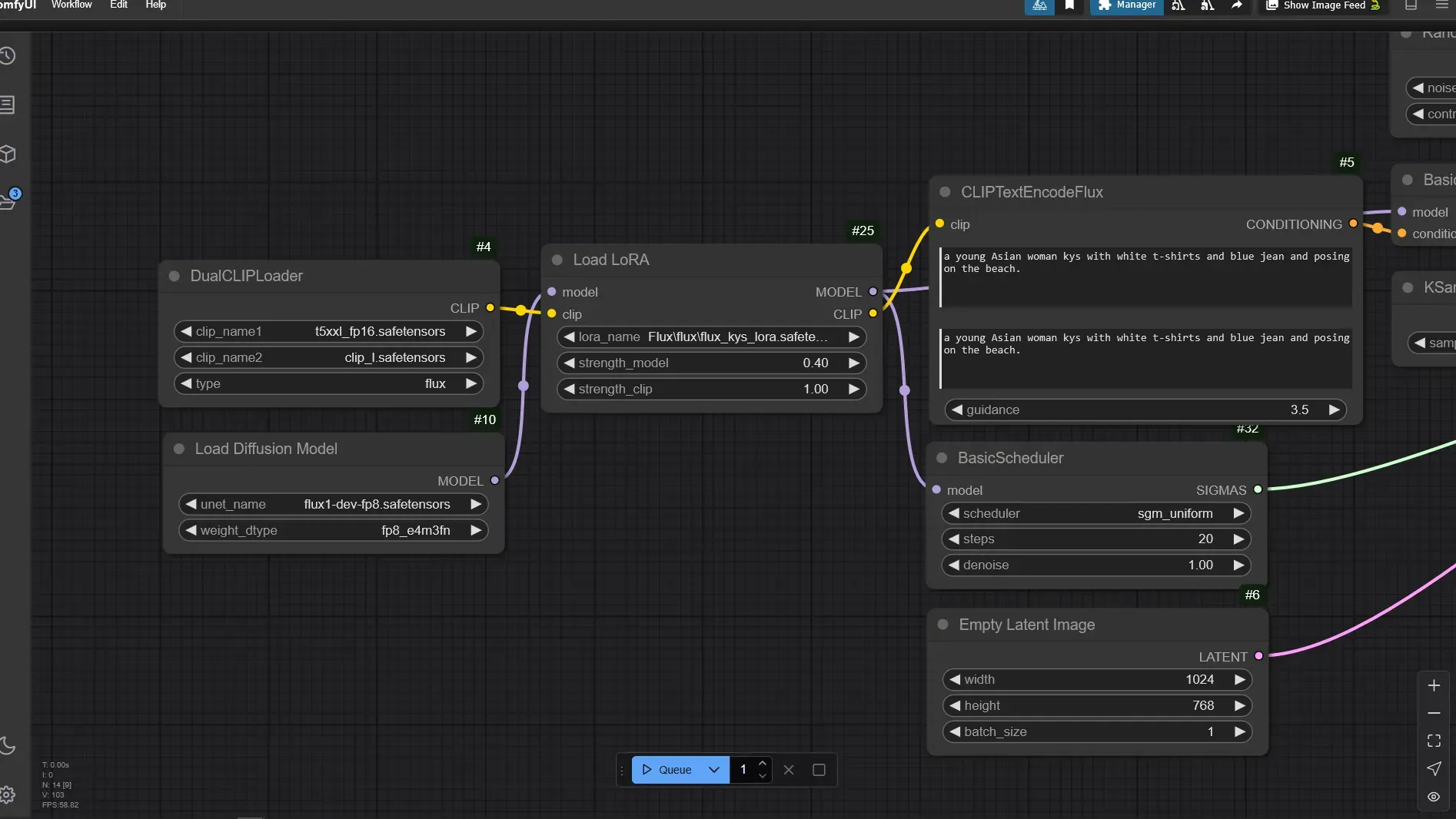
프롬프트는 Fal.ai에서 테스트하기 위해서 추론 했을때 사용했던 프롬프트를 그대로 사용했습니다. ClipTextEncodeFlux에 아래와 같이 입력했습니다.
a young Asian woman kys with white t-shirts and blue jean and posing on the beach.
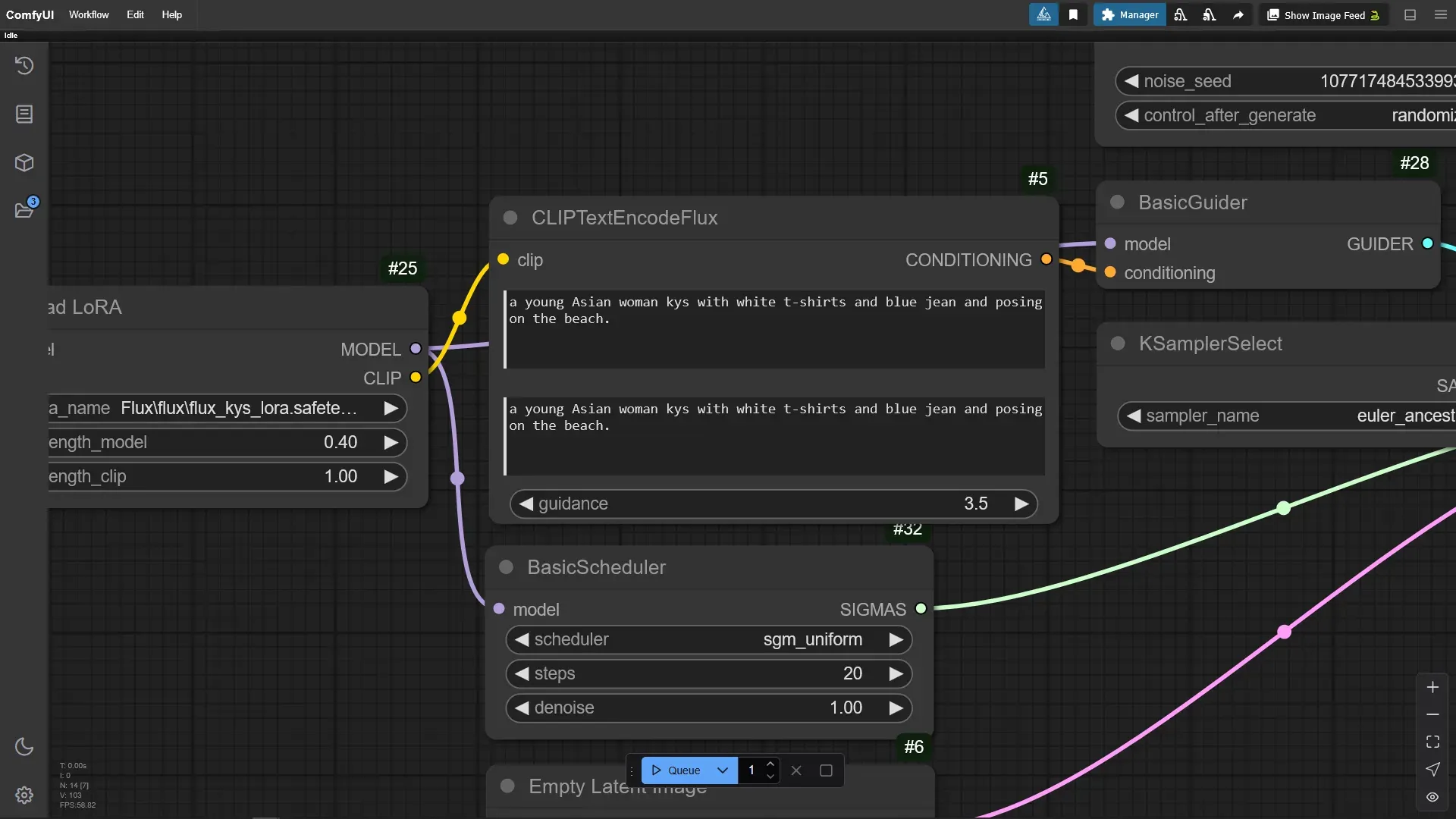
2-5. ComfyUI에서 제작한 LoRA를 이용해서 이미지 생성하기

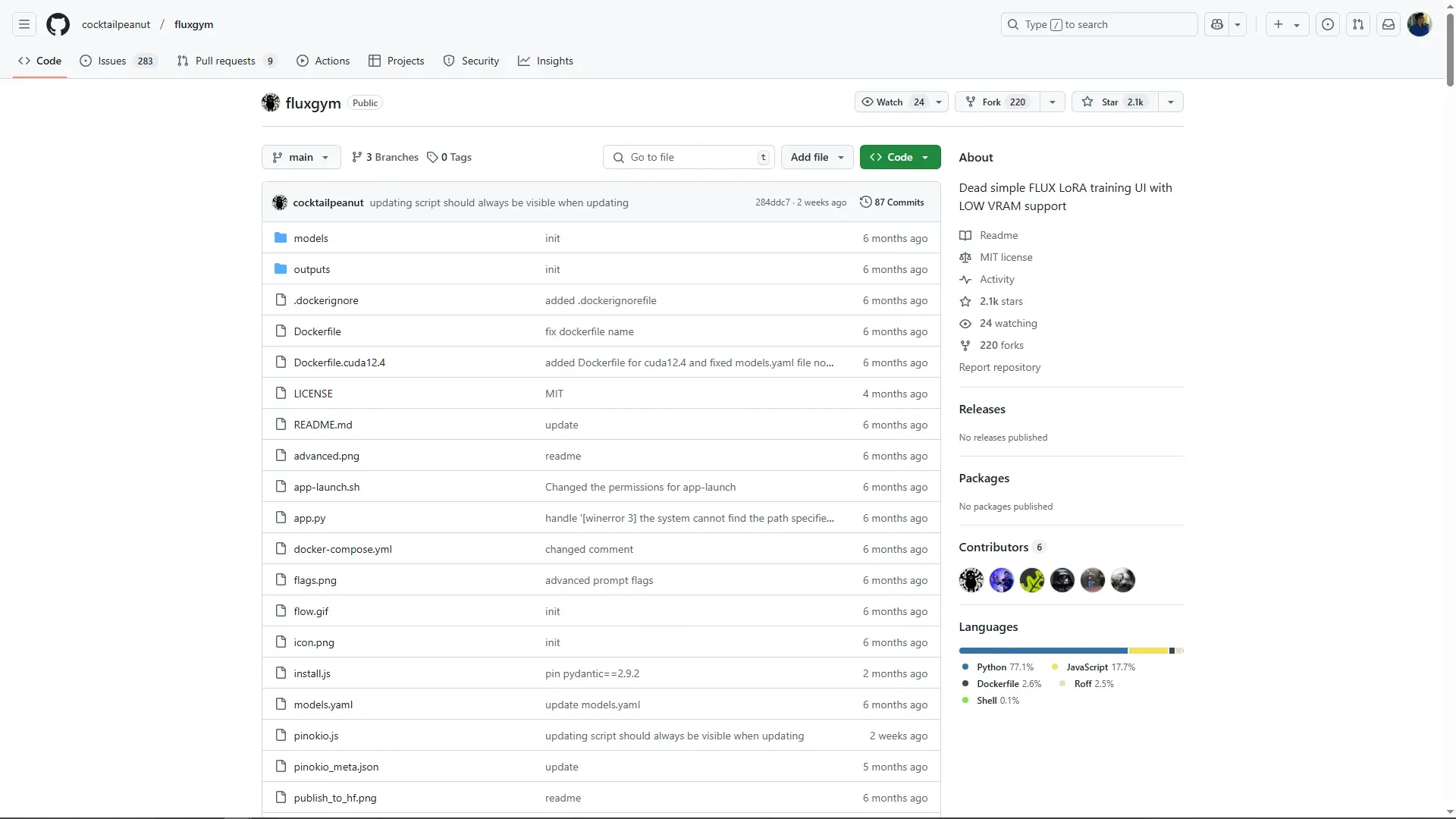
FluxGym은 BlackForest Lab의 Flux 모델을 더욱 쉽게 추가 학습(튜닝)할 수 있도록 설계된 툴입니다. 이 도구는 모델 학습 과정에서의 반복적인 실험과 조정을 간소화하여, 사용자가 효율적으로 모델을 만들 수 있도록 도와줍니다. FluxGym의 저장소는 아래의 링크를 통해서 접근할 수 있습니다.
설치
FluxGym설치는 해당 저장소의 Readme를 참고하시면 됩니다.
FluxGym은 설치에 대해 다양한 편의를 제공하고 있습니다. Pinokio를 사용하거나 프로젝트를 다운로드받고 파이썬 가상환경을 셋팅하고 프로젝트에 관련된 파이썬 모듈들을 설치하기만 하면 됩니다. 또는 Docker를 사용하시면 됩니다. 여기서는 Window플랫폼에서 venv를 사용하고 있다고 가정하고 설명하도록 하겠습니다.
venv를 실행시키고 python app.py로 FluxGym을 실행합니다.
python -m venv env
env\Scripts\activate
python app.py
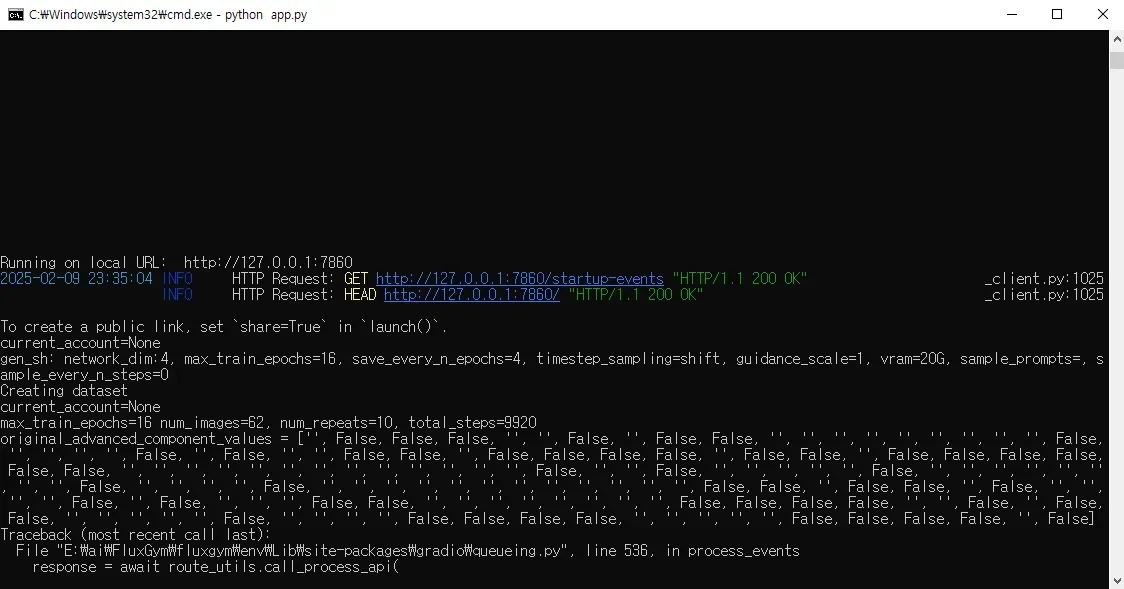
정상적으로 실행하면 아래와 같이 cmd에서 localhost:7860 포트를 통해서 연결된 브라우저로 바로 FluxGym 웹UI가 뜨는 것을 확인할 수 있습니다. 자동을 웹브라우저가 뜨지 않을 경우 위의 포트로 웹 브라우저에서 접근하면 됩니다.
2-6. FluxGym 에서 추가 학습
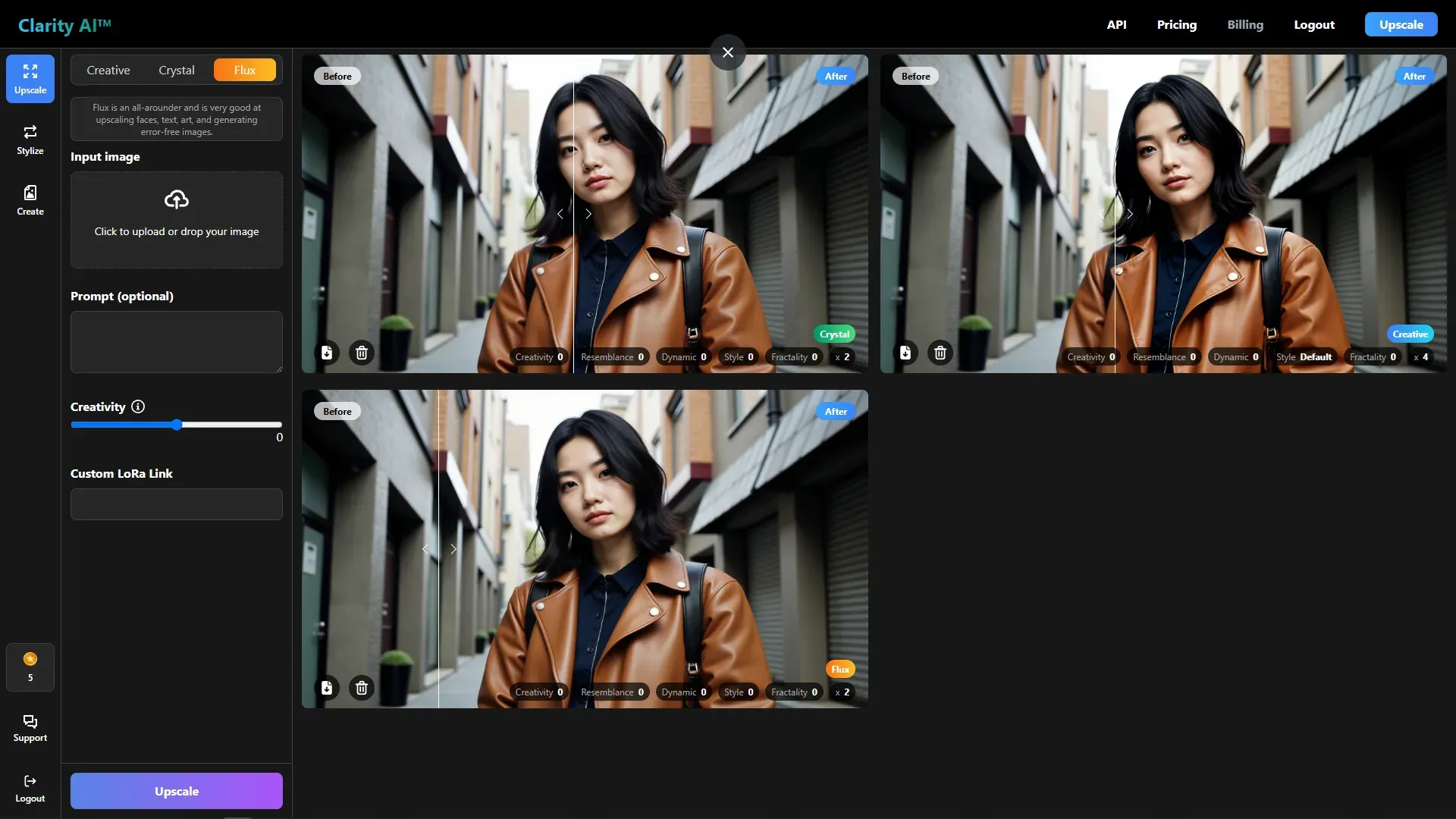
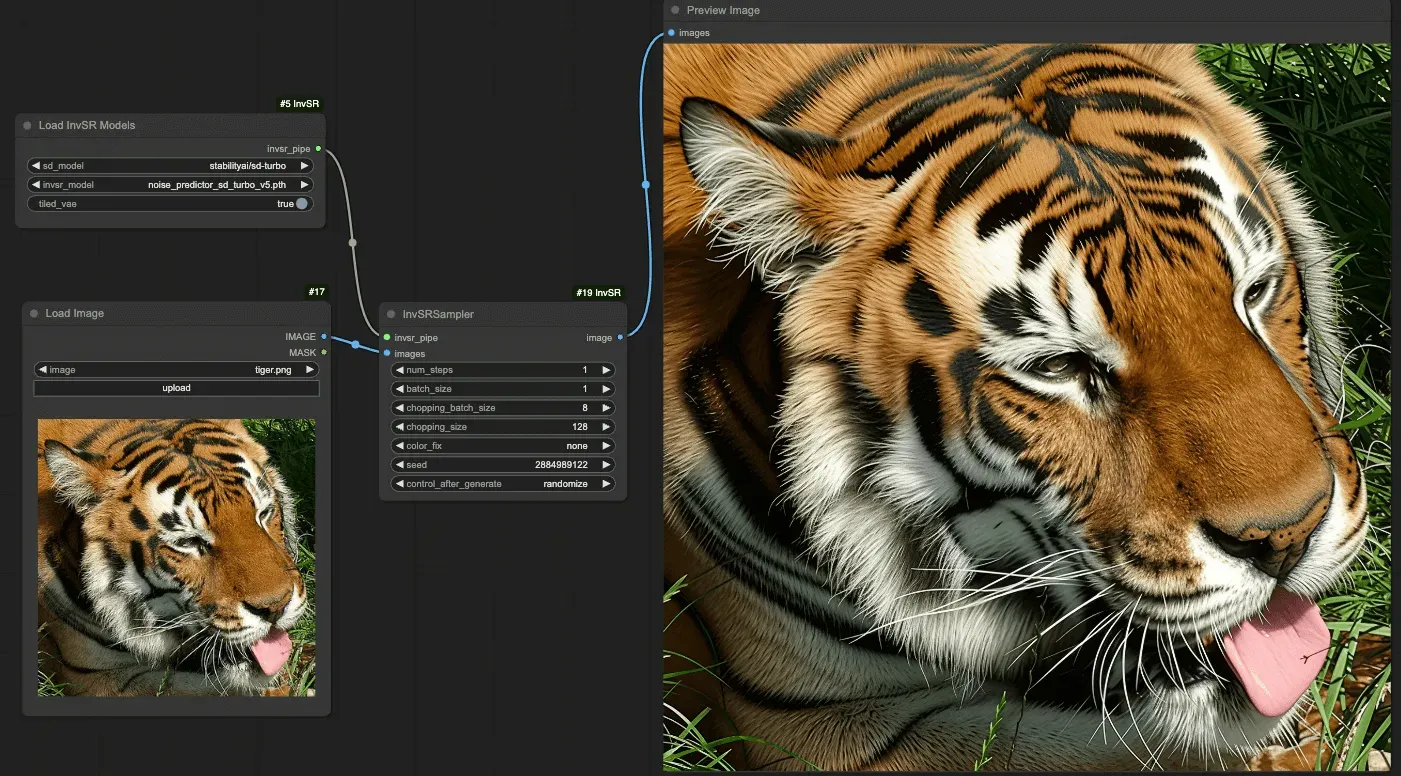

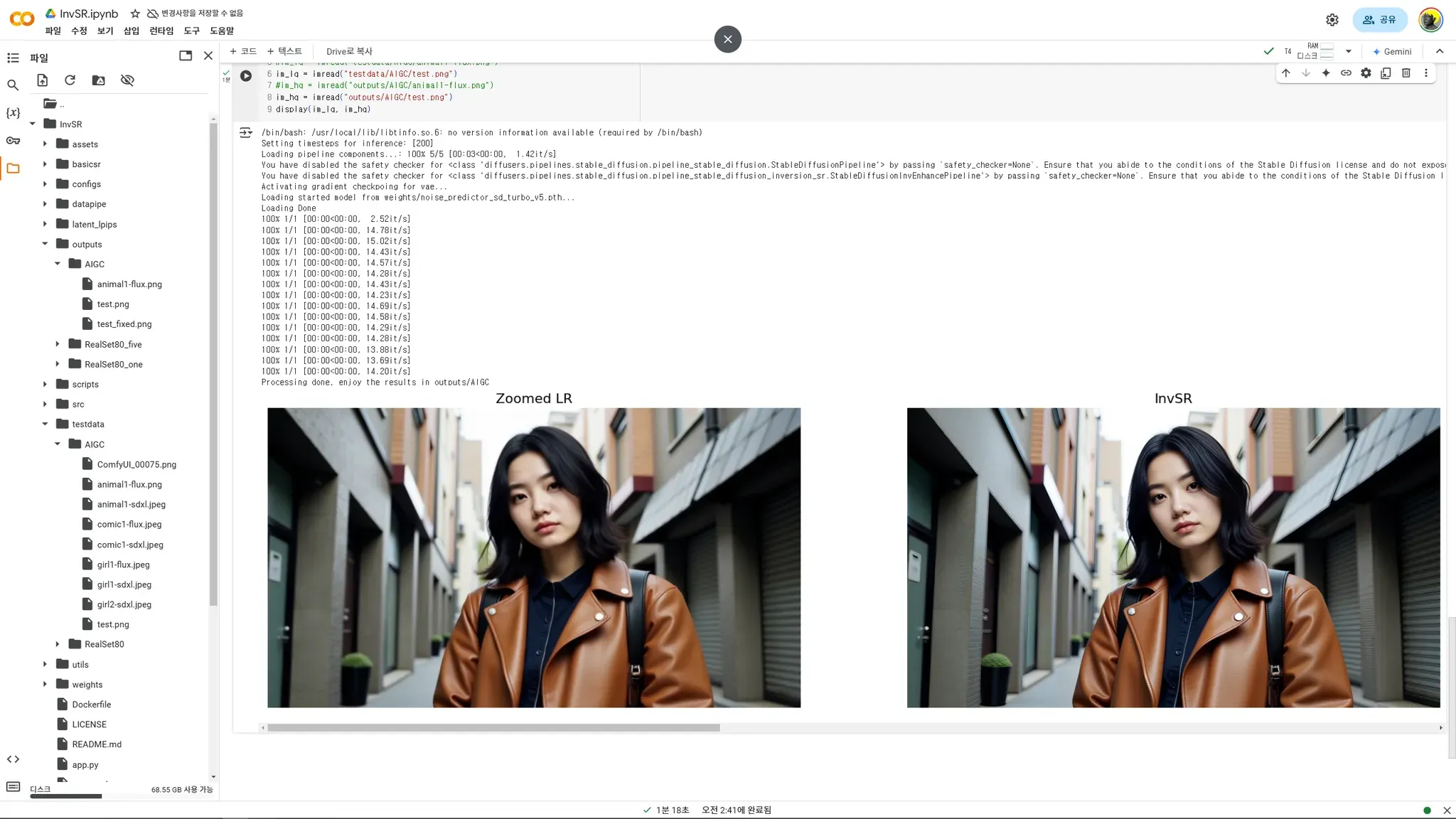







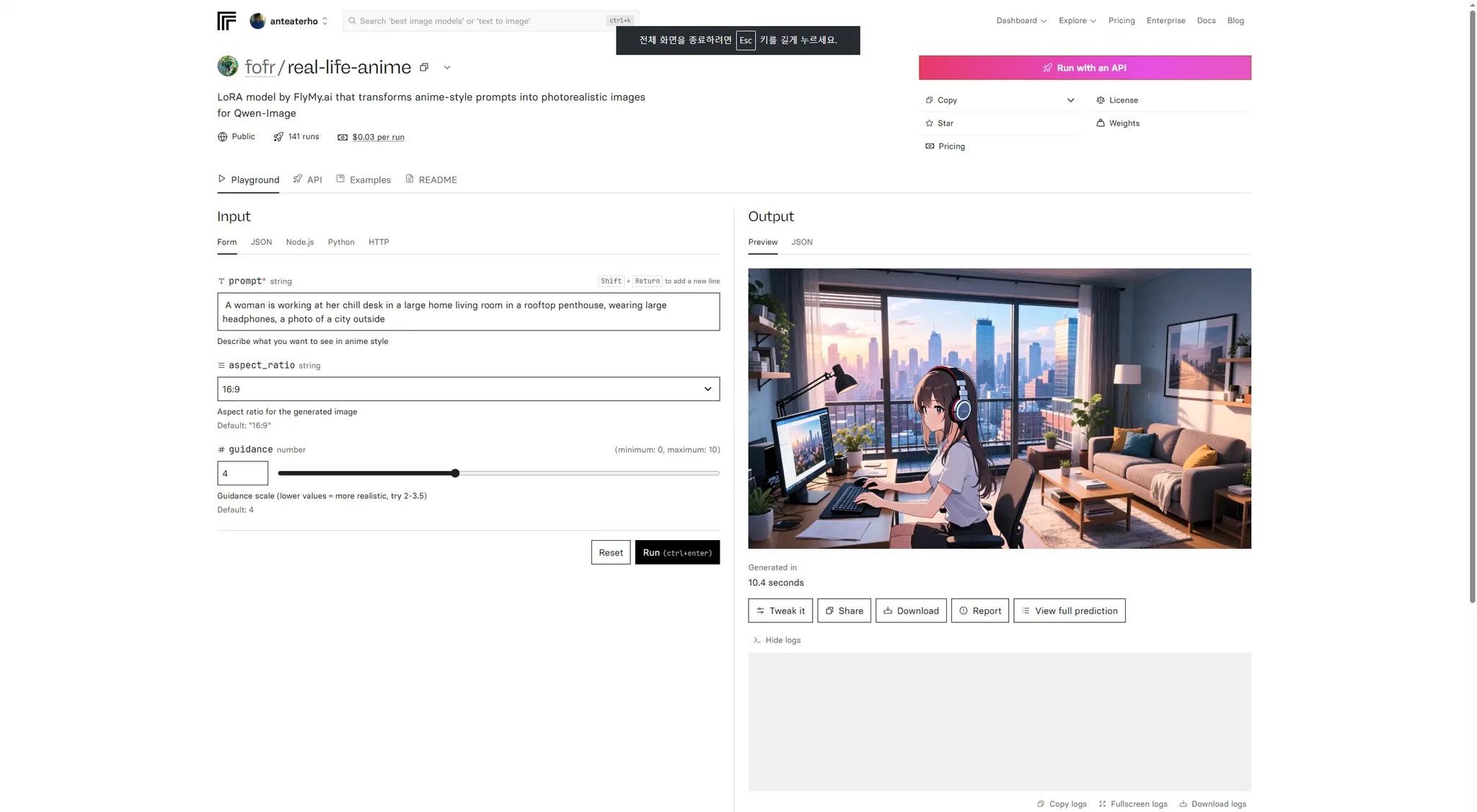
갤러리 보기
Search



Archiving
갤러리 보기
표
Search



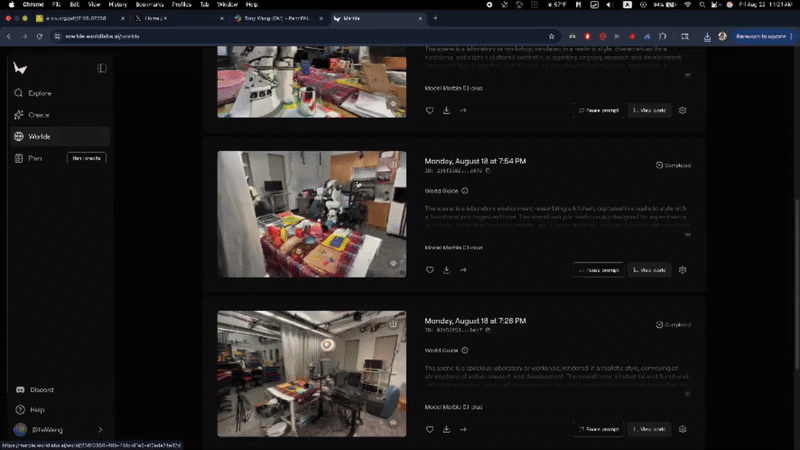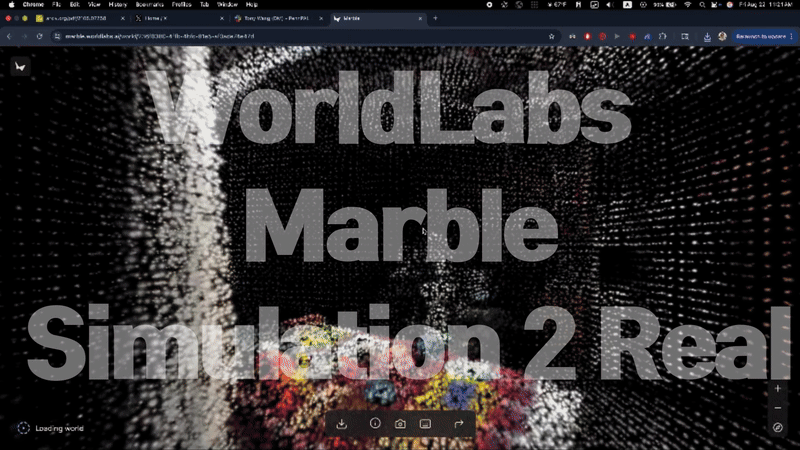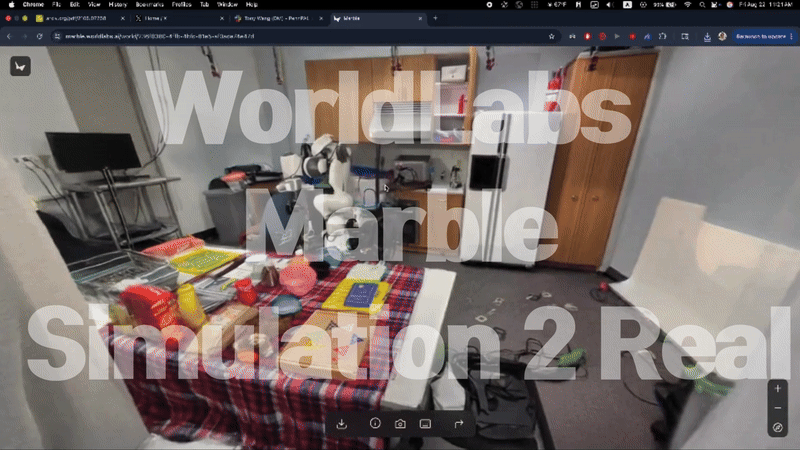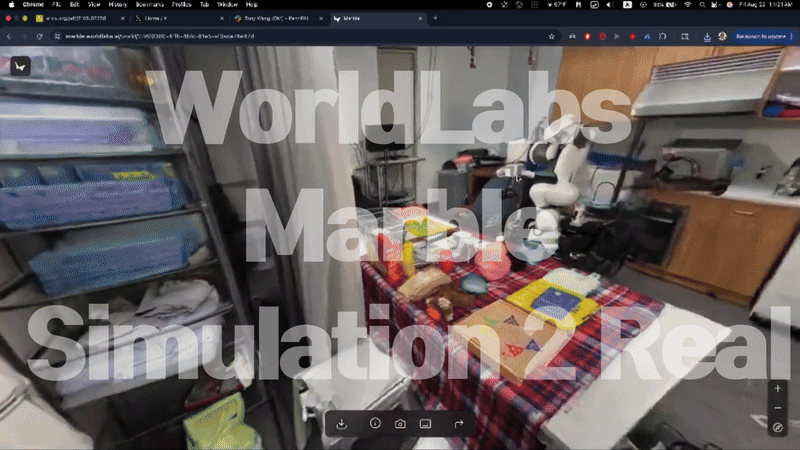










Grok Imagene
Google Nano-banana
nano-banana는 LMArena 플랫폼에서 발견된 출처 미상의 이미지 생성 및 편집 AI 모델로, 레딧과 X(트위터) 등 SNS를 통해 화제가 됨. 공식 발표나 개발사 정보는 없으며, 커뮤니티 추측에 따르면 Google(Imagen/Gemini)에서 개발한 비공개 모델로 추측하고 있다.
구글이 8월 20일에 열리는 "Made by Google" Pixel 이벤트를 앞두고 다양한 AI 업데이트를 준비하고 있는데 GEMPIX (제미니 픽셀?) 이미지 생성 업그레이드가 제미니 출시를 위해 준비 중이라고 한다. 이는 LM Arean의 nano-banana 모델과 관련이 있을 수 있다.
관련 커뮤니티 테스트






주요 특징:
• 성능: 뛰어난 프롬프트 충실도와 공간 이해 능력, 텍스트 기반 이미지 편집 가능. Imagen 4나 GPT-Image-1 같은 최상위 모델과 비교되며, 자연스러운 이미지 생성에 강점을 보임.
• 약점: 작은 글자나 세부 텍스트의 왜곡 문제 존재.
• LMArena: LMSYS 운영의 공개 벤치마크 플랫폼으로, 사용자가 두 모델의 결과를 비교·투표하며 순위를 매긴다. ‘나노 바나나’는 https://lmarena.ai/ 에서 무작위로 테스트 가능하다.
LMArena란
nano-banana
















테스트 결과
360 이미지를 생성하고 그라운드에 해당하는 부분은 DepthMap을 생성해서 바닥의 지오메트리를 디스플레이스먼트로 살짝 튀어나오게 해서 약간의 3D 효과를 내게 한 것 같다. 360 파노라마를 생성하는 Blockade Lab(https://www.blockadelabs.com/)과의 차별점은 이 부분인 것 같다. 인터랙티브하게 움직이는 것은 카메라와 환경구와 바닥이 충돌하지 않는 범위에서만 움직일 수 있다. 프로모션의 영상은 그것을 3D 작업 환경에 가지고 가서 물리나 시뮬레이션을 돌리는 예시를 보여준 것 같다.
소개
“Hunyuan3D 월드 모델 1.0출시 및 오픈 소스로 공개. 이 모델을 사용하면 단 한 문장이나 이미지만으로도 몰입감 넘치고 탐험 가능하며 인터랙티브한 3D 세계를 제작할 수 있다. 업계 최초의 오픈 소스 3D 월드 생성 모델로, CG 파이프라인과 호환되어 완벽한 편집 및 시뮬레이션이 가능합니다. 게임 개발, VR, 디지털 콘텐츠 제작 등에 혁신을 가져올 것이다.”


참고 테스트
@camenduru 테스트 영상의 하단을 보면 그라운드의 메쉬가 별도로 있는 것을 확인할 수 있다.
Hunyuan3D World Model







List
Table
갤러리 보기
Search
Load more
List
Table
갤러리 보기
Search
리스트 보기
Gallery
Search
List
Table
Gallery view
Search
List
Table
Gallery view
Search
Load more